java基于TCP的socket数据包拆分方法
前不久写了socket相关的程序,服务器是java,客户端是flex。一开始就想过所谓的拆分数据包的问题,因为数据包结构是自己定义的,因此简单的写了几行数据包的验证。开发测试中完全没有发生什么情况,但是发布到外网之后却出现一些非常奇怪的问题,其中最主要的就是通信过一定时间之后,数据包验证处理模块就会出错然后就抛弃一部分数据包,这就是所谓的“丢包”吧,但是我使用的是基于TCP的socket,所谓因为网络问题导致的数据包没有发送与接收成功这种情况应该是不会出现的。
看了几篇文,发现这种现象被称作“粘包”,我觉得还是挺贴切的。经过一定时间的思考和测试,大致了解了其中的原理,按照现在的情况来看,应该是没什么问题了。于是在此总结一下,如果哪天我发现一些新问题或更好的方法,还是会来继续补充这篇文章的。当然各位路过的前辈觉得其中存在错误什么的也请指出。
首先在讲程序之前,还是先说一下TCP通信。TCP和UDP的最大区别就是TCP维护了连接状态,而这个状态我们可以理解为一个畅通的流通道,即stream,当然流的传输内容归根结底还是byte。于是将流的通信进行假设,假设存在一条引水管道,从远方输水过来,我们在这边等待水的到来,并使用容器接收流出来的水。
此时存在以下几种情况:
- 假设这个输水管道在操作过程中不会断掉。
- 先进先出,先流进管道的水一定是先到达。
- 某一状态,(在输水管没有断掉时)流量无法保证,甚至某段时间没有水。
- 我们的容器(缓冲区)大小固定,即每次接收的水量存在最大值,超多将无法接收。
在以上情况作为前提,再回归编码。基于TCP的socket可以通信的前提是连接没有断开,连接断开事件可以从两个方面进行判断。流断开,这read()为-1,SocketException或者IoException。分包的前提是socket可以正常通信,不论网络延时多么严重,这些TCP协议会去处理。我们仅仅关心通信既可。现在最优情况,即实验室环境,或者是内网,服务器与客户端延时不会大于一毫秒,此时只要我们接收输水的容器够大,基本就可以完成正常通信。
但是互联网情况就非常复杂,数据包要经过无数网络软硬件设备,延时不可避免,但是TCP协议会像输水管道那样,保障数据包的顺序和保证不会丢失。所以这时我们可以控制的只有接水的容器。查看一些简单的网络通信知识,网络数据在传输的时候存在缓存现象。简单的说,就是连续发送N个数据包,他们可能被缓存起来一起被发送。这种情况就是粘包,当然对于接收端来说,我们不能保证每次都能正好的完整的接收数据包,更多时候是x.y个数据包。
再次回到输水模型,我们的容器等待水的到来,现在存在超时时间即每次等待水来有一个最大时间,超过这个时间,即使没有接到一滴水我们也要处理这个水桶。所以我们得到水桶的水理论上是大于等于0,小于等于水桶的容量。现在开始从代码角度来说明。
现在我们有一个byte[] buffer = new byte[MAX_LEN],即数据包读取缓冲区,int len = connection.read(buffer)。read方法使用buffer读数据流,len为实际读出的数据长度,此长度大于等于0,小于等于MAX_LEN。等于0自然不去处理,等于-1认为连接断开,当然read方法会抛出异常,即当读取数据过程中,连接出错。
现在我们获得一个buffer,即缓冲区。里面存在len长度的可用数据。我们要做的就是根据自己的协议结构,将这个buffer转化为遵循我们自己的协议的数据包(packet)。进而交由后面的业务逻辑代码处理。
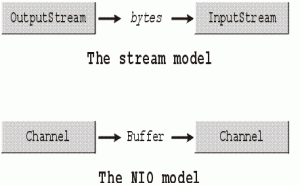
此时我们定义自己的通信协议一个byte的包头,用于数据包合法性验证,两byte数据包长(一般用4byte,即一个int),剩下内容为可变长度的数据包体。现在我们拿到buffer,这时候就有分包(粘包),和组包(数据包没有接收完整)两种情况。感觉似乎比较头疼,但是实际上获得packet我们仅仅需要知道的是数据包的真实长度,即2byte的内容,转为short后假设为PACKET_LEN。然后我们只要拆分和等待PACKET_LEN个长度的byte即可,那才是我们真正需要的东西。当然,这个过程我曾经陷入过误区,然后经人指点后才发现我关注了很多没用的东西,结果增加了代码的复杂度。之后就上代码了,现在我的结构是服务器使用nio,然后nio框架将buffer封装为java.nio.ByteBuffer。其底层实现还是固定长度的byte[],它做的仅仅是封装了一些byte操作的快捷方法而已。既然它封装了,我们就要利用一下。
ByteBuffer.remaining(),此方法非常好,返回剩余的可用长度,此长度为实际读取的数据长度,最大自然是底层数组的长度。于是这样看来这个ByteBuffer更像是一个可标记的流。ByteBuffer.get(byte[]),从ByteBuffer中读取byte[]。
首先把ByteBuffer当做流来处理,即read(ByteBuffer)之后ByteBuffer.flip()。此时重置到流的前端。这个java代码是按照最原始的思路写的,写的比较难看,但是比较清晰。有时间再优化下算法,应该可以写的再漂亮一点。
1 | public List<byte[]> getPacket(ByteBuffer buffer) throws Exception{ |
如果觉得不好看,可以先看下面的Flex实现方法,思路是一样的,但是看起来非常简洁。
1 | private function socketDataHandler(event:ProgressEvent):void{ |
首先拿Flex说,Flex库和Flash实际是一样的。flex中的socket中有自己的缓冲区,所以只管到时读数据即可。所以我们就等packet的长度,获得数据包长度之后等待这个长度的字节。但是java就不同,java的底层缓冲区我们没办法控制,于是就需要自己写一个东西缓冲没有接收完整的数据。就是代码中的_packet,他是一个初始化长度为0的byte[]。思想就是等我们需要的东西,等到就读出来,剩下不完整的就存起来和下一次合并再判断。当然这种东西都是有规律的,我觉得还没有发现这个规律,如果发现的话,代码长度应该会像Flex那么简明吧。
规律这种东西真的很美妙,我们总结出规律之后就完全跳出了复杂和容易出错的步骤,进而去关注更重要的事情。就像我获得packet之后,刚开始算数组索引,由于是可变长度,里面的内容也是定义的可变数据,刚开始计算packet的每个内容的时候非常繁琐。之后我后来发现了索引规律,简单的说就是index += packet[index] + n。然后就完全从数据结构里面摆脱出来。
嗯,差不多就是这个样子了。