树莓派网络爬虫

v1.0 1st Edition
经过一段时间的折腾,在实际使用中发现了一些非常有趣的东西,并且也逐渐意识到树莓派的不足之处。关于树莓派的从零开始请参考《树莓派的简单应用》,主要介绍从入手配置到一些简单的使用。之前的想法是做一些提高生产力的工作,但是因为三月底的最后一天晚上看到的推文,开始了一些算是前置的工作,这些很多都是和爬虫相关的。
TL;DR点击列表跳转
前言
又到了熟悉的四月,回想起坑了几年的文章觉得是开始写的时候了。开始之前我想起了之前在网易云音乐看到的一些有趣的评论,但是想不起来是在哪看到的,并且找不到了。然后突然出现了一个想法(我又一个大胆的想法),弄个爬虫抓网易云的热评。虽然之前用Java做过网页抓取和分析,但是这样大规模爬虫还没有接触过,并且在树莓派上仅仅是开一个jvm估计就占用不少资源(虽说python这种效率也高不到哪里去)。搜了搜好像Python和node做爬虫都非常的方便,就个人来说Python更加顺手一些,所以就开始了写爬虫之旅。
准备工作
树莓派是一个低功耗设备,所以它适合做一些长时间运行的任务。但是同时其又是一个性能比较低的嵌入式设备,不要说和PC进行比较,就是和现在的一些手机比起来也差距很大。所以在抓网易云这样规模的网站时我隐隐约约的觉得可能心有余而力不足。
首先需要说明的是爬虫是一个并行任务模型,而Python的多线程实际上并没有真正的并行计算能力,所以其对计算密集型任务并不友好。但是好在爬虫是IO密集型,包括网络IO和磁盘IO。同时多线程也没有办法让多核心CPU发挥效果,所以要配合多进程。
对于存储比较方便的还是NoSQL,在此推荐MonogoDB,为了减少磁盘IO可以使用Redis这种内存KV数据库。好像有些网游(主要是手游)和网站都推荐这种架构,把热数据放在内存中,并使用适当的策略和磁盘进行同步。也许是遇到了好时候看官网上说以前Redis是没有对windows和树莓派的进行支持的,现在windows有了第三方支持和树莓派进行了官方支持。
1 | # linux做更新基本都有这个,没必要多说了 |
这里redis和mongo在安装之后都在自启动的,redis配置文件在/etc/redis,mongo启动启动脚本在/etc/init.d/mongodb,配置文件在/etc/mongodb.conf。
1 | # 添加MonogoDB服务到service.msc |
windows是没有自启动和服务配置的,如果放在服务管理器里面的话使用使用上面的命令。安装之后就可以使用net start MongoDB和net stop MongoDB启动和关闭服务,或者直接打开服务管理器service.msc手动控制。
之后是python多版本的问题
1 | # 只有一个版本或默认版本的安装 |
如果一个系统安装多个版本的python则使用python -m pip install安装指定版本的包,这里的python是这个版本的可执行python的命令名。即使用这个命令可以直接进入指定版本python命令行,如windows系统现在安装多版本后python是进入3.x3的,而py是进入2.x的。
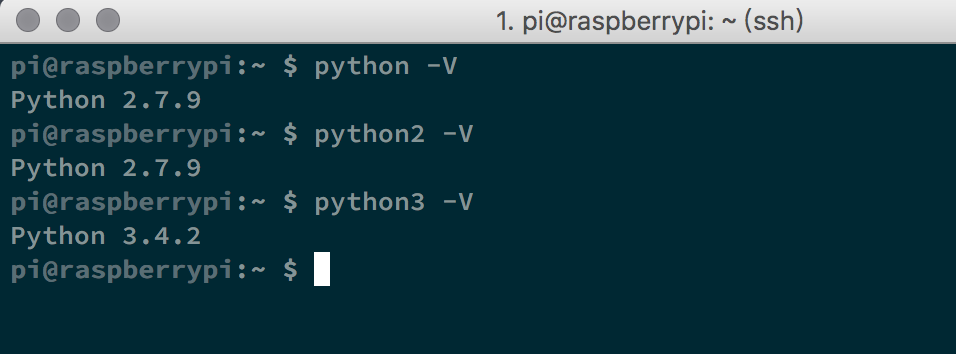
而树莓派默认是安装了python2和python3,默认情况下python2进入2.x,而pyhton3进入3.x,如上图,但是默认的python命令是进入3.x的,这和windows又不一样,所以要特别注意不要安装错了版本。
span id=”net_easy_music”>网易评论
首先说一下结果在树莓派上全速跑了五天之后,抓取了十四万条热门评论,可以说基本上公认的比较火的歌曲专辑和评论都抓取到了,比如传说中周杰伦的晴天。但是在看日志后发现存在大量的请求被反爬虫拦截的问题,虽然每次请求都是随机user-agent并且共享请求session的,但是由于没有足够的代理池。经过测试发现很多小众的音乐都没有抓取到,所以这次经历并不算非常成功。这也促使我做一个长期有效的代理IP池的想法,这段内容将在下文中说明。
1 | from concurrent.futures import ProcessPoolExecutor |
这里使用ProcessPoolExecutor做多进程管理,其在python2中是不存在的需要使用pip单独安装。网络请求使用requests,在python2中也是不存在的需要单独安装。
网易云和其它的音乐网站不同的一点是,单曲没有暴露给用户分类信息。用户第一次进入使用FM对用户进行筛选,长期使用之后用户会自己搜索或者通过每日推荐自己进行过滤。这些单曲肯定是有常规的那些便签和属性的,只是它不对外暴露我们无法获得。针对这种情况有的朋友通过歌单进行抓取,通过歌单的标签和分类来确定单曲的分类。而网易云音乐对个去的收录有比较严格的要求,因此对单曲唯一性也有比较好的控制。
鉴于以上的情况,对抓目标有这样几种方式。
- 专辑:抓取所有专辑。专辑可以获得歌曲信息,在专辑中再抓取歌曲信息,根据歌曲信息再获得评论。
- 歌手:抓取所有歌手信息。再获得专辑信息,进而获得歌曲和评论信息。对于很对没有归类的音乐都存在VA这样的歌手,所有理论上是可以获得全部信息的。
- 歌单:歌单是用户个人通过挑选歌曲建立,理论上其应该是无法覆盖到全部歌曲的。不过没人听的歌曲那么评论也不会很多,那么获得的价值也不是很大。
1 | import requests |
以上为网络请求的基本方法,由于这里还没有IP池所以get_url(url, header_=header, cookie=None) 方法中的proxies参数就为空,否则可以放入一个IP列表。对于整站抓取就需要使用session,如get_session_url方法中的requests.Session(),可以跨请去保存某些参数,也能在多请求中保存cookie。其内部使用urllib3的connection pooling功能,所以其主要的作用是想同一主机发送请求其底层TCP连接将被重用,进而加快请求提升性能。更多详情参见文档《Requests高级用法》。
另外我对于XPATH有了新的理解,从最开始学Java开始就有各种读配置文件或者XML文件的问题,这其中也试过了各种各样的类库,在Java环境中特别是Android环境中,快和资源占用少成了首要的选择。后来在处理HTML的时候遇到了jsoup,先不管它效率如何,其支持的jQuery选择器真的让我大开眼界,简直相见恨晚。后来我实现了一个订阅系统,从RSS/FEED流中读取信息,如果必要就直接抓取网站的正文,JSOUP为HTML清洗、特征值与关键字提取提供了非常方便的功能。所以在第一次接触Python的时候我不自觉的就是用了与jsoup相似的BeautifulSoup。但是在看了一些爬虫项目后发现原来lxml库,其基于XPATH的查找方式给了我很深的印象。于是我开始尝试回归XPATH。
IP代理池
IP代理池的作用的在大规模抓取的网站的时候避免被对方的反爬虫系统拦截,也就是一个IP的访问限制。
IP代理池逻辑上是一个非常容易理解的系统,其分为两部分。
- 代理地址收集:通过定时任务收集一些公开的代理服务器地址。国内有很多网站如快代理,66等会收集网络上各类代理服务器的地址和端口,我们可以对这些信息进行收集。
- 代理地址测试:代理地址需要定期检测其有效性。我们收集的这些地址毕竟是免费地址,其可靠性和失效性都无法长期保证,所以我们需要定期对其进行检查。
1 |
|
此方法为直接对抓取的地址进行检测和验证,通过则保存入库,否则尝试删除数据库已有的相关数据。装饰器@robust仅仅是做日志统计和异常处理。
1 |
|
jobs_check方法为定期检测方法,其通过域名检测其下获得的代理地址。最开始对IP池的估计是每个网站有数千个状态良好的可用IP,但是在实际运行之后发现其可用IP的数量在不断增长。即便是周期任务间隔比较久,但是随着数据量的增加单个任务执行时间增长,当执行时间查过定时周期之后,会造成任务的重复运行,给线程调度带来问题,增加系统压力。所以这要重新设计。
1 | import requests |
以上代码用于检测代理地址的可用性,其原理为使用此地址访问指定网站,正常则此代理可用。
对于反爬虫机制,这些定时任务实际上运行时间间隔比较长,所以可以躲过大部分反爬虫机制,直到遇到了验证浏览器真实性的反爬虫机制。即有些网站第一次访问的时候执行一段加密的JS代码,此代码动态生成客户端cookie,然后刷新网页并使用此cookie重新请求地址。如果服务器检测不到这段cookie则拒绝访问。
Pyv8顾名思义就是python封转过的chrome JS v8引擎,通过此库我们可以在代码中模拟执行JS代码。
1 | import PyV8 |
如上述代码,可以通过提取网页中的JS片段并运行获得cookie,然后使用这段cookie重新请求即可。但是现实并不如这么顺利,我们都知道chrome是一个版本更新非常快的软件,其中JS引擎v8也是频繁的修改。好在windows下有专门编译过的安装文件,而Linux下是通过源码编译安装,那么就无法保障在某一个时段代码正常编译。于是我在树莓派上安装pyv8就存在各种问题,目前正在寻找替代的方案。
进程与线程模型
由于最开始爬虫测试,发现树莓派的一些不足。因此准备做一些长周期对系统要求较低的工作,比如前面说的IP池,再加上前几天一直使用的P站接口无法返回数据,就更进一步的坚定我的想法。而P站这种任务更是有甚至几小时的运行间隔,毕竟每天晚上能看到自己喜爱画师的最新作品就足够了。也正式因为有这种需求所以需要web端。
对于web这里使用Flask框架,虽然最开始一直使用tornado,其提供的定时功能也很不错。但是tornado对web界面的处理还是比较弱的,比较Flask有jinja2和Mako这种模板引擎,在实现web界面的时候会非常方便。
1 | # app.py |
以上为入口文件app.py,其提供了多种接口为的是在uwsgi容器中运行或直接调试运行。
1 | #configs.py |
以上为配置文件configs.py,可以看到对于配置信息是非常灵活的,我们甚至可以将这些内容直接硬编码到app.py文件中。对于线程和进程调度这里使用flask_apscheduler,其本质就是对apscheduler的一层封装,使用方法和apscheduler一致。而这里只添加了定期刷新点击看板和一对IP池获取和检测任务,对于更多的任务和UI层展示正在重新设计中。另外对于数据源的切换,这里主要是指同一个连接的不同数据库,可以直接在持久化类里面方便的进行。
使用心得
树莓派中安装了Linux系统,其作为一个容器几乎提供了所有Linux PC应有的功能,但是毕竟是一个嵌入式设备,对于过高的计算压力,其本身还是无法胜任的。最开始的爬虫测试中使用4个进程,任务开启后即便是IO密集型,CPU占用率依旧飞速增长,而散热片更是无济于事,温度更是以可感知的状态下疯长,没有办法只有开启散热风扇,说实话那小风扇噪音还是有点大的。
即便是后来以为压力非常小的IP池维护,CPU使用率也长时间在80%到110%范围内波动。后来听说树莓派官方发布的计算模块,但是看介绍那是专门给硬件工程师用的,而且一套下来也价格不菲,更为关键的是估计用来跑爬虫依旧够呛。
而替换方案比如NAS(网络存储)和家用小型服务器,这些本身价格也偏贵使用起来反而性能过剩。另一方面PC做长时间运行也是我一直反感的。所以对树莓派的使用还是要量力而行。
代码
此项目使用的代码有很大的局限性,毕竟都是针对个人需求的。但是即便如此将来完成了,还是会把代码共享出去的,
以上。