聊一聊Spring - 开篇
一、前言
Spring这一技术栈发展到现在从某种程度上说是非常不可思议了,这最重要的是Spring随时代的变化而变化。在服务隔离、微服务与前后端分离等大行其道的今天,Spring衍生出的Spring-boot成为Java后端开发的首选,让Java这种“沉重”的语言一下子“轻盈”了起来。仿佛也如同node.js和python一样快速的搭建出开发环境或Demo一样。而这其中Spring boot提供的基于注解的开发方式几乎不依赖各类配置文件的方式,让大部分开发人员摆脱了繁杂的XML配置文件。
但是就行我之前说过的那样一旦一项技术过于工程化,那么这个行业的从业人员可能就面临比较严峻的形式。因为这时已经不需要太多的专业技术人员,需要的更多是“操作员”和“执行者”。伴随着Spring boot在Java后端大行其道,即便是现在企业项目在选型和做技术架构的时候也开始向微服务方向靠拢。而拥有Spring Cloud方案的Spring boot技术栈其实在事实上已经成为了首选,特别是那些刚刚从传统SSH/SSM项目转型出来的开发团队。
在接触了不少传统企业级应用开发者和一些新接触这一技术栈的朋友,我能明显的感觉到Spring boot技术栈的工程化在减少开发负担的同时也弱化了开发者对Spring这一传统技术体系的认识。伴随着Spring boot2.0以以及Spring5.0的发布,我觉得有必要对这Spring 整个技术体系做一个梳理。说到Spring给我印象最深的依旧是IoC和AOP,那么今天就先简单的聊一聊Spring AOP的故事,作为整个系列的开端吧。
本文作为Spring系列的第一篇文章,只是借助Spring AOP相关知识点进行开篇说明。并不是枯燥的技术文章。
二、容器
我们在谈论Spring的时候实际上是在谈论整个Spring体系,而从技术上说Spring实际上只是指Spring Framework。虽然在日常开发中我们常用SpringMVC做指代,但是请不要忘记SpringMVC也仅仅是在Spring FrameWork基础上是实现的MVC框架而已。Spring Framework的核心是Spring容器,在这个在意义上这也是整个Spring的起始点。所以不夸张的说要理解Spring Framework比先要理解Spring容器。
Spring容器说的通俗一点就是Spring对bean的管理,只有被Spring管理的bean才能使用Spring提供的各种功能。说到Spring的容器其实本质上是在说Spring IoC容器,可以不夸张的说Spring Framework核心就是IoC容器,
当然SpringMVC也有自己的容器,叫做web容器或Servlet容器。DispatcherServlet在初始化时会创建自己的IoC容器,用来管理自己特有的bean。
对bean的管理可以从几个维度上理解。
1、Bean的注入
将对象交由IoC管理由以下几种途径。
1.1、xml
XML注入应该算是最经典的写法,是Spring Framework一开始的就存在的。
1 | <beans> |
虽说有了注解的存在可以非常直观的进行bean的注入和管理,但是对于大规模的bean管理个人还是推荐使用xml的方式。因为xml的方式可以对分散在各处的bean进行统一管理,关于注解与xml混合使用的方式可以参考下文的测试章节。
对于微服务来说如果划分粒度合适,再加上比较好的项目结构,那么使用注解的方式将会是首选。
1.2、工厂注入
工厂注入通常和构造器注入放在一起讨论,而工厂注入又分为静态和实例工厂。
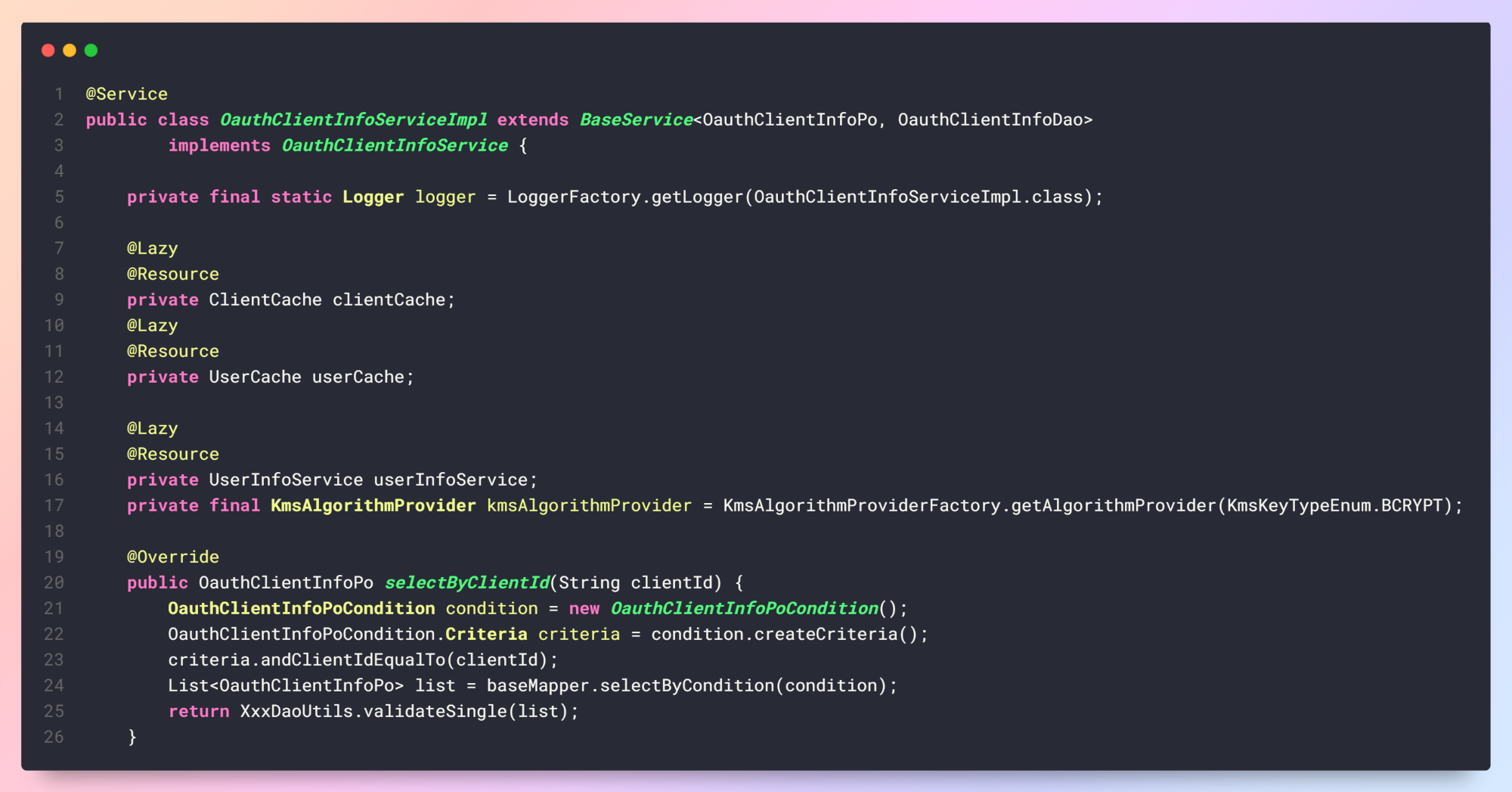
1 | public class CarFactory{ |
如上CarFactory类中有实例方法createCar()也有静态方法createStatic(),那么用这两种方法来创建Bean就是所谓的工厂注入了。
1 | <!-- 工厂实例 --> |
以上属于比较标准的工厂注入实现了,不过Spring并没有为我们提供官方的注解实现工厂注入的方法。这是因为如果要进行工厂注入那么实际注入类要在继承链条上,如果在工厂方法中设计一种通用的方法实现那么势必要对整个项目的class做扫描,并通过另外的方式(比如额外的注解)来限定工厂的实际产出对象。从框架上考虑这有些得不偿失,所以如果要使用注解实现工厂注入,那么可以根据实际情况实现用有限的固定类型对象产出来做实现。
1.3、注解
使用xml对bean进行管理其繁琐性不仅整个项目可能会存在大量配置文件,其次大量需要记忆的xml标签才是另开发者感到繁琐的地方。在bean存在复杂依赖关系,特殊的注入配置和下文说明的AOP配置时。我们就会明显的感觉到配置文件这种约定形式的规范,比起注解这种工程性的硬性要求随着开发周期的延长越来越引起开发者的反感。
Spring boot就是使用各种各样的注解来简化配置。当然这个前提依然是服务隔离和功能的拆分,正是因为不同于传统企业项目那种产生大规模配置信息,这种同样类似于约定的注解形式才能相对的简化开发和部署。
注解终究属于编程的范畴,当你不知道某些注解的关系时直接在IDE环境下点击去看源码,无疑是最有效的方式。比如@RestController与@Controller的关系(@ResponseBody)。
注入到IoC容器的注解究其根本都是@Component,无论是@Controller还是@Service。如果搞不清注解到能能不能自动注入到IoC容器,还是那句话点进去看注解的源码看它是@Component有没有关系。而@Bean注解更像是<bean/>标签的代码表现形式。

同时对于Scope配置也非常简单,如使用@Scope注解,并且注解里也写的清清楚楚在BeanFactory中有几种类型,在WebApplicationContext有几种类型。
2、依赖注入(DI)
相信不少朋友在初次接触Spring的时候还不知道Spring Framework和SpringMVC(Web)到底是神马的时候,就肯定听被控制反转(IoC/Inversion of Control)和依赖注入(DI/Dependency Injection)各种概念一愣一愣的,当然还有下文的面向切面编程(AOP/Aspect Oriented Programming)。
看到上文对Spring IoC容器表层的使用做简单介绍之后,就会发现实际上IoC的核心就是Bean的管理。而当Bean之间存在各种依赖关系时IoC容器就需要对注入做专门的控制,就是这样将Spring容器管理的Bean注入到被需要的地方就产生了依赖注入的概念。
Spring IoC容器是Spring Framework的核心。直观的说Spring容器的启动也就是
ApplicationContext的启动与初始化过程。在各类应用场景中可能有多个Spring容器存在,比如常规的JavaEE Web项目、Spring Cloud项目等。
当一个问题上升到一个重要概念的时候,就说明它已不单纯是一个孤立问题。在没有涉及AOP的时候我们要时刻记得我么的一切操作都是基于Bean,而这个Bean一定是被Spring IoC容器托管的。同时Spring的基本思想就是面向接口编程,这个接口的某个具体实现类的实例我们没必要去在意。因为我们操作的对象可能是接口的实现,也可能是这个实现的一个代理。
DI可以看作是IoC的一种实现方式。
当我们谈IoC的时候实际上重点不在依赖,而在于Bean本身的的功能,当缺少依赖时我们向IoC容器索取。但是我们谈DI的时候却是以依赖的角度去思考谁需要我。到了这一步似乎水到渠成很容易理解,但是在面对实际设计问题的时候我们要面对两个问题。即面向对象的程序设计和面向接口的模式设计。
从某种角度上来说面向对象和面向接口也仅仅是层次和维度上的差异,面向对象更多的是解决现实世界的抽象,面向接口是这种抽象的实现手段。
- 面向对象:正是由于面向对象的存在,
Bean之间的关系错综复杂,复杂的依赖关系带来了Bean生命周期管理的复杂性。 - 面向接口:面向接口导致了
Bean具体实例的复杂性与不确定性,给注入带来困难。
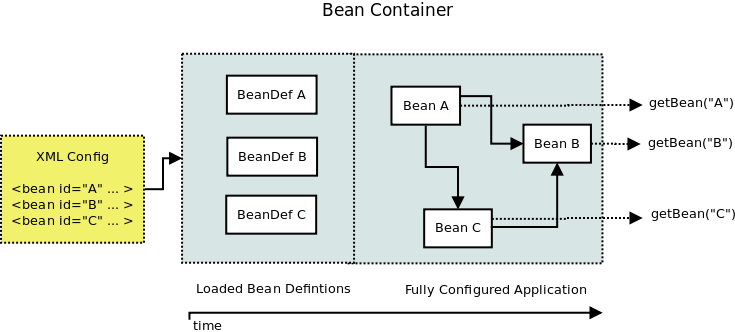
如上图所示出现的循环依赖问题算是最容易理解的情况了。在xml配置中一切都是使用最终实现类做<bean/>的声明,这相对注解的方式来说反而又显得格外的清晰。说到这里我们又要回到Spring Framework的初衷,替代“笨重”的EJB。Spring作为Java平台的最受欢迎的企业级开发解决方案,它怎么也绕不过Java EE的规范。所以Spring以一种相对轻量化的方案实现了一部分JavaEE和EJB的规范,如Servlet、JMS等。
2.1、注解注入
在进行xml依赖配置的时候有autowire选型,可以是byType也可以是byName。JavaEE中默认是byName而Spring容器默认是byType,这点在注解javax.annotation.@Resource和org.springframework.beans.factory.annotation.@Autowired就可以清楚的看到。
1 |
|
如上述代码,我们向Spring容器中注入两个UserInfo类的实体Bean,虽然他们类型相同但是名称分别为info和userInfo。
1 |
|
现在我们尝试在Service等的某个UserService的实现类中注入一个UserInfo实例。那么问题来了,如果我们用@Resource那么默认它是byName查找所以UserInfo实例只能叫做userInfo或者info,否则就会注入失败。那么如果你非要不按照规范来比如我就是要叫做userInfo1,那么还有救就是使用@Resource(name = "userInfo1")。
而使用Spring的注解@Autowired它只能按照byType,所以如果容器里只有一个UserInfo对象那么依然会相安无事。但是像上文的AopConfiguration中两个同类型的bean那么依旧会注入失败,不过同样的我们有@Autowired + @Qualifier("info")可以补救。

说了那么多不如来一张图直观,上图可以看出想
注意以上注入注解不需要相应的
getter/setter,并且没有修饰符限制。同时@Bean("name")注解同样支持托管bean的重命名,于是我们对方法的命名也能更随意了。
测试
1 | ApplicationContext applicationContext = new AnnotationConfigApplicationContext(AopConfiguration.class); |
最快速直观的测试就是我们使用上述代码的applicationContext.getBean("name")来查找容器里的bean,就会检验到在使用注解的情况下各种情况下Bean的唯一标识符。
2.2、@Component托管
@Component一类注解在托管当前类的对象给Spring容器时如果没有指定唯一标识,Spring容器将使用类名首字母小写为此对象的标示符。
1 |
|
- @Service() -> bean(‘userServiceImpl’)
- @Service(“userService”)-> bean(‘userService’)
由于我们在Spring boot环境下常用@Autowired注解,而由于是自动找UserService接口的实现所以我们可以随意更改成员变量名而存在注入问题。
由于@Component的从属关系,相应的
@Service、@Controller都支持Bean重命名。
2.3、依赖倒置(DIP)
当我们谈论DI的时候有时候也会想到DIP,即依赖倒置(Dependency Inversion Principl)。
- 高层次的模块不应该依赖于低层次的模块,他们都应该依赖于抽象。
- 抽象不应该依赖于具体实现,具体实现应该依赖于抽象.
依赖倒置其实没什么好说的就像其定义一样是一种准则,一种设计模式,将依赖目标抽象化以达到解耦的目的。更加通俗一点讲这是一种编程思想,为了降低耦合度而规定不依赖具体类而是依赖于接口,同样要求我们面向接口编程。
那么我们再来回顾一下控制反转(Inversion of Control),一般分为两种类型:
- 依赖注入:Dependency Injection,也就是DI
- 依赖查找:Dependency Lookup
3、BeanPostProcessor(BPP)
之后专门讲容器的时候会专门对BeanPostProcessor(BPP)进行详细的说明,毕竟BPP在Bean的管理中起到了非常重要的作用。正是有了BPP的存在容器的作用被大大增强,比如对各种注解的实现,扩展出更强大的AOP等。
1 | package org.springframework.beans.factory.config; |
以上是BPP接口,从这个接口所在的包名就几乎已经大致可以猜到它的大致作用。
Typically, post-processors that populate beans via marker interfaces or the like will implement {@link #postProcessBeforeInitialization}, while post-processors that wrap beans with proxies will normally implement {@link #postProcessAfterInitialization}.
从这个接口的注释上大概看的出其运作模式,其中post-processors翻译为后处理器。当我们实现此接口并注入到Spring 容器。会发现正常托管的普通Bean都会经过**Initialization方法。而且BPP的对象会在普通托管Bean被创建之前被创建,随后普通Bean创建之后经过BPP处理再进入Spring容器。
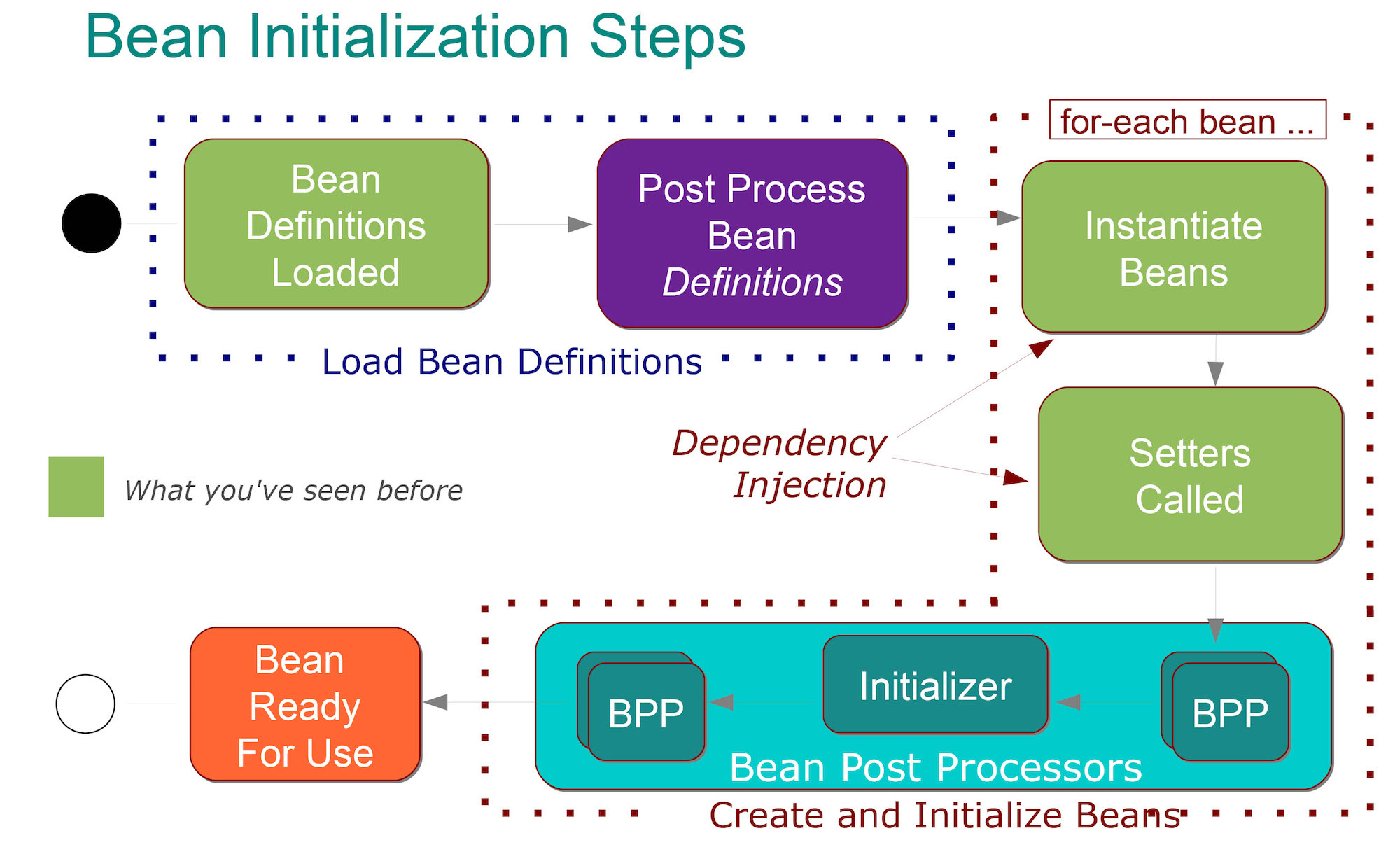
上图非常直观的说明了BPP在Bean生命周期中的作用,可以看到在经过BPP之后Bean才能被我们使用。所以当我看到这个图的时候我就想,代理岂不是可以在这里实现?进而AOP织入也在这里实现?
3.1、BeanPostProcessor的作用
有任何关于Spring核心功能不解的地方都可以直接从ApplicationContext及其子类下手,而关于启动与初始化的操作可以直接查案ApplicationContext的抽象实现AbstractApplicationContext中的#refresh()方法。
1 | package org.springframework.context.support; |
可以看到有许多我们非常熟悉的名词,那么BPP中的Before和After又是指的的什么呢?这里就要从Bean的生命周期管理了,而bean的话又牵扯到BeanFactory我们就在之后专门讲Spring容器的时候做详细说明吧。那直接找一个和注入相关的BeanFactory说明吧,比如AbstractAutowireCapableBeanFactory。
1 | package org.springframework.beans.factory.support; |
而其中所使用的各种BPP是在非常上层的抽象类abstract org.springframework.beans.factory.support.AbstractBeanFactory中被添加的。这里可以看到所谓的Before和After仅仅是在方法invokeInitMethods被调用的之前和之后。而invokeInitMethods方法也仅仅是为了实现了org.springframework.beans.factory.InitializingBean接口的Bean做特殊处理,这里包括对Bean的授权以及调用InitializingBean#afterPropertiesSet()方法。所以我们大部分只要关注BBP的After即可。
3.2、对AOP的支持
在开启注解@EnableAspectJAutoProxy后会使用AopConfigUtils类向BeanDefinitionRegistry中注册AnnotationAwareAspectJAutoProxyCreator。所以以注解为例其最终实现类为org.springframework.aop.aspectj.annotation.AnnotationAwareAspectJAutoProxyCreator,但是真正的功能上的实现是AbstractAutoProxyCreator。
1 | package org.springframework.aop.framework.autoproxy; |
如上述代码postProcessBeforeInstantiation(Class, String)来自接口InstantiationAwareBeanPostProcessor,其是BeanPostProcessor的直接接口。其主要作用是拦截有自定的TargetSource并生成代理对象,都则走BeanPostProcessor的postProcessAfterInitialization方法。
1 |
|
以上方法会根据wrapIfNecessary并继续调用getAdvicesAndAdvisorsForBean方法判断当前中是否有可以被切面拦截。如果可以就生成代理对象这样才能实现AOP功能,而具体如何生成则根据不同的ApplicationContext而不同,有的是有JDK动态代理,也有是有CGLIB的情况。
三、AOP
面向切面编程即Aspect Oriented Programing,其和面向对象的OOP是从不同维度上考虑问题。面向对象的程序设计目标是对现实世界的抽象,而实现手段是类的封装与继承,所以在大多数情况下对象之间是链式关系,不管是继承还是相互协作。而这种关系反应的也是现实世界的抽象,以及我们的对问题的思考方式。
如果说面向对象是纵向,那么面向切面(AOP)就是横向,颇有工程方面的思想。很多时候我们需要很多和业务操作无关但是又必须有的功能,毕竟业务来自需求但是设计和实现却要牵扯到方方面面。从整个项目角度来说项目和功能是首要的问题,我们不能为了技术问题来修改业务和功能,也不能因为设计的问题影响业务流程。为了让与业务我关的功能与业务有过多的耦合和代码上的侵入,面向切面编程就被推广开来。这些所说的功能就有如日志、权限、事务等。
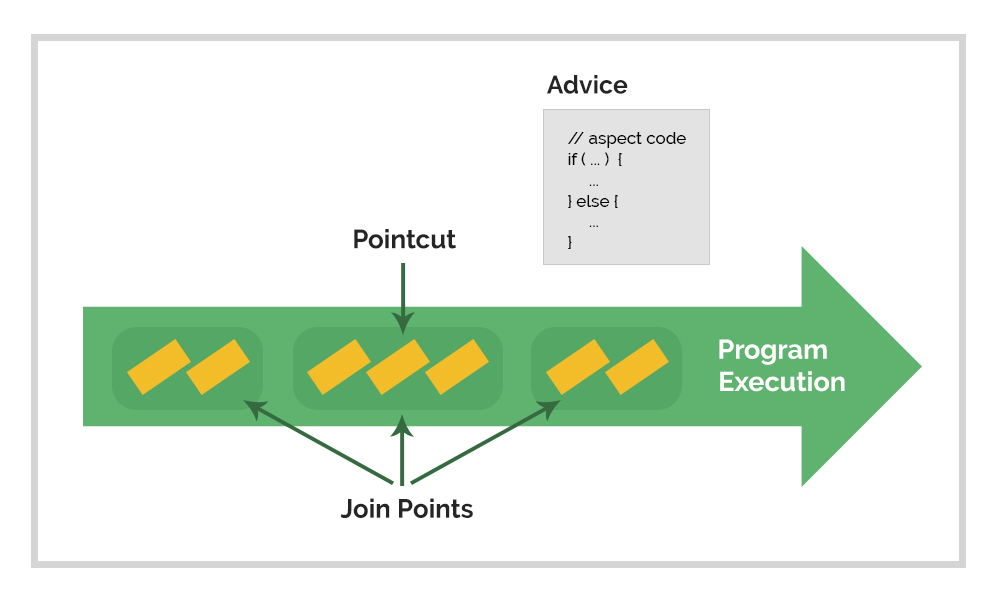
上图比较直观的说明了AOP几个重要概念以及如何在程序设计中其作用的。主要包括如下概念:
- 连接点(JoinPoint):表示可被拦截的方法。
- 切点(Pointcut):连接点中可以被切入的方法。
- 通知(Advice):切点被触发后需要执行的操作。
- 切面(Aspact):主要包括切点和通知,主要作用是定义通知与切点的关系。
- 织入(Weaving):把切面代码织入到目标方法的过程。
如果第一次看到这些感念肯定会比较迷惑,但是一旦与实际联系起来就会非常自然的接受了。
3.1、 AspectJ
AspectJ是Java领域实现AOP的规范性技术,甚至在很多时候当我们谈起Java的AOP都会直接和AspectJ画上等号。固然AspectJ本身如神一般的实现了AOP,在没有了解其原理后都会感觉不可思议。但是用过AspectJ的都知道其特有的语法和特有的acj编译器在实际使用中有不少麻烦,而且总体来说其对代码的侵入性还是有点高了(相对Spring来说)。不过在Spring不合适使用的场景,AspectJ还是能发挥非常不错的效果。
AspectJ之所以地位这么高,主要是其为Java的AOP技术带来了两项贡献:
(1) 切面语法
- 切面语法真正做到了将切面的控制权交由切面控制,切面决定了哪些方法可以被代理
- 从逻辑上不需要侵入业务代码,做到代码解耦合
(2) 织入工具
- 不需要额外的配置文件
- 不需要干涉对象的创建
- 在编译阶段插入业务代码
3.2、AspectJ工具
虽然我们在大部分时候不直接使用AspectJ尤其是在使用maven管理的项目中,不过有一些东西还是需要稍微了解一下的。
- aspectjrt.jar:包括运行时注解和一些静态方法。
- aspectjtools.jar:包括acj编译器,在编译期酱Java文件或class一级aspect定义的切面织入到代码中。
- aspectjweaverjar:提供了一个java agent用于在类加载期间织入切面。提供了对切面语法的相关处理等基础方法,供ajc使用或者供第三方开发使用。这个包一般我们不需要显式引用,除非需要使用LTW。
都说AspectJ提供的是静态织入,包括编译前织入和编译后织入。但是实际上AspectJ完整的支持编译时织入、编译后织入、加载时织入三种,这些以后在专门的AOP文章中进行说明吧。
值得注意的是
AspectJ在1.5时提供了@AspectJ注解,而Spring在2.0的时候开始跟进。我们在Spring中使用的AOP注解几乎都来自AspectJ。
3.2、Spring AOP
Spring AOP有一下特点:
- 与Spring IoC容器结合。
- 支持方法级别的切点。
- 引入
AspectJ的注解。 - 基于动态代理的方式实现。
那是那句话与Spring有关的功能几乎都绕不开Spring容器,越高级的功能越是如此。Spring的AOP功能在哪里实现上文的BPP章节中已经有了简单说明,这里主要聊一下比较本质的东西。
Spring AOP使用了AspectJ的注解和切面语法,但是具体实现和AspectJ没有关系。Spring AOP使用了自己一贯的代理技术,即JDK代理和CGLIB代理。这些都属于动态代理技术,并且都是在运行时动态生成,并不是生成中间的class文件。关于动态代理想必在一开始接触ORM的时候就已经有所了解,这里也不在赘述了。
3.2.1、AOP-execution
应用切面语法实际上我们更多关注的是execution表达式。
execution(modifiers-pattern? ret-type-pattern declaring-type-pattern? name-pattern(param-pattern) throws-pattern?)
表达式中依次是:访问修饰符、返回值、包名、方法名、参数列表、异常。这里的问号表示可选,否则就要使用*占位符表示全部匹配。而参数列表使用..表示模糊匹配。
现在定义切点
1 | public class AopPointCut { |
注意这里只有切点,并没有声明切面,这个切点在之后还会用到。以上是拦截UserService接口的实现类中的findUserByName方法,并且要求此方法第一个参数为字符串。比如实际上匹配到的是实现类UserServiceImpl,这里的好处就不必多说了。
现在的表达式语法已经允许
java.lang.String只写成String了。
这里简单介绍一些比较常用的写法:
"public * *(..)", "*com.example.aop.*(..), "* *ByName(..)"
这类写法非常直观使用*号替代的就是模糊匹配的内容,这也是最常用的手段了。可以全部匹配,可以针对某个包,某个类,某个方法等。
"bean("userService")","UserService+"
针对bean或者针对某接口实例的匹配,在实际使用中更加偏向抽象业务,针对一系列功能等。
3.2.2、表达式类型
主要使用特殊的关键字与execution()配合使用,如within、this、target、@target等。这些内容过于多在之后AOP专题中进行说明,这里只做简单的介绍。
1 |
|
如上述代码@Before通知引用切点pointCut()(注意这是方法名),并使用args关键字引入参数name。很多朋友对target和this比较困惑,其实只要跑一遍代码比看再多文档和资料都直观。
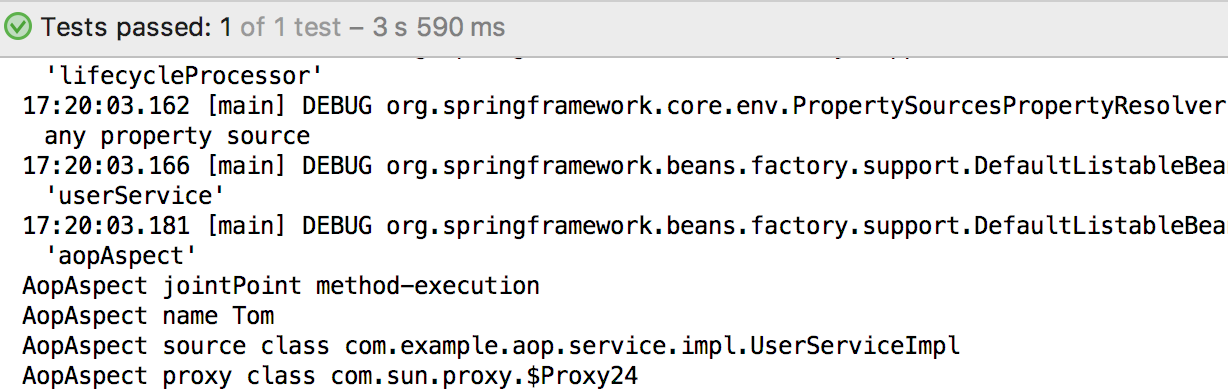
看结果可以非常直观的发现target获得的对象是原始对象,this返回的是代理对象。这里使用AnnotationConfigApplicationContext启动明显发现是由JDK生成的代理,而使用ClassPathXmlApplicationContext启动则返回的是CGLIB生成的代理。
对于参数的传入特别是target和this传入的参数更多的时候直接在接收的参数列表中使用Object,由于这里直接已经在表达式中过滤了UserService所以也省去了类型转换。
关于逻辑表达式
||和&&目前也支持了
and和not写法,而target(com.xxx.xx)这类的过滤方法甚至支持!target()这样的写法,真的是非常灵活了。
1 |
上文切面类AopAspect中的check方法,以上四种语法是等价的。这里实际是在说明切点的引用。如对切点AopPointCut.callPointcut()的引用实际是多次调用传递进而引用到了私有且点internalPointcut()。
3.2.3、排序
对于AOP中切点与通知的排序问题在不少场景中是比较真实存在的,而这里又遇到Spring容器的排序问题。Spring支持@Order注解和org.springframework.core.annotation.Ordered接口排序。
1 | package org.springframework.core; |
对于排序的支持由org.springframework.core.OrderComparator类支持,而根据代码可知其只支持Ordered接口排序。
1 | package org.springframework.core.annotation; |
对于排序的通用支持由AnnotationAwareOrderComparator提供,其实只看名字也能猜的差不多(笑)。覆盖的父类findOrder中就能看出不禁判断了接口也判断了注解,而这里又引出了抽象类org.springframework.core.annotation.OrderUtils。OrderUtils里面提供的各种静态方法实际上已经提供了获取排序接口和排序注解的功能,如果在实际使用中可以直接拿来用。
值得说明的是排序接口
Ordered和排序注解@Order是可以混合使用,即已用注解排序和实现接口排序是可以放在一起比较的。不过一个类同时使用注解和排序接口那就要看排序方法中先判断哪一个,由于这是由内部方法实现,所以不能保证未来某一天判断顺序会变化,因此不建议这样使用。
四、测试
这里的测试是指快速测试,比如我要测一个想法是否可行,比如上面的切点语法是不是有效。
1 | public class SpringAopTest { |
如上述代码,分别提供了使用xml和注解两种方式快速加载测试方式。当然实际情况可能非常复杂,作为临时测试可能要同时使用xml和注解。说来说起还是对bean的管理,属于Spring容器的内容。
注解为主可以配合@ImportResource使用。
五、最后
本来作为Spring系列的开篇文章稍微聊一聊,比如稍微说说容器和AOP的东西。虽然很多细节都没有说,但是一不注意还是讲了这么多。那就这样吧。