数据库树形结构查询
在此探讨下数据库中简单树形结构的查询和相关操作。本文探讨的前提条件为通用SQL语法,不涉及特有类型数据库的特有方法,如Oracle之类,所以这里介绍的方式是标准SQL,也就意味着其有最广泛的通用性。
数据库树形结构目前个人想到的是三种实现方式,并且各自有各自的优点,具体使用要看具体的环境,当然了与编码人员的偷懒程度也时候有关的。你可以选择开始设计的非常完美,消耗大量时间,之后一劳永逸。或者是每次都随便写写,将来不停的缝缝补补。
首先说明树形结构的价值,或者是使用意义。自然了,本文讨论的数据库是实现标准SQL的关系型数据库。
软件特别是业务系统主要目的就是方便完成某些功能性操作,在注重业务的领域就更加强调业务的操作,关系型数据库与现在比较火的NoSQL,Key/value数据量的最大区别就是强调的是数据之间的关系和数据安全。所以业务类软件和数据库的设计必然的会抽象客观世界的逻辑和操作流程,数据存储方面自然强调其关系性。
而关系型数据库对数据的表现和存储方式是二维表结构,即每条记录拥有若干的属性和其相应的值,所以这样横向的看一张表你会想到什么?从java的思想去看那就是Bean,一个可持久化的实体对象。一张数据表由若干行表示,在这里纵向看自然是一个列表或数组结构。所以在持久层概念之下我们可以忽略掉查询操作的二维表结果集返回结构,直接将数据表抽象为一个存有若干十九话对象的列表或数组结构。由于关系型数据库表为固定列结构,所以在抽象的时候非常考验设计能力,在大型的业务系统中也许或经常看到若干按照一定规律递增的无业务意义的空白列,这就是一种使用冗余的方式达到向后兼容的设计方式,个人觉得宁可新建表关联来维护逻辑结构也比这样留下所谓的扩展字段来的好一些。貌似有些跑题了。
所以当我们抽象客观世界的时候就会免不了遇到属性结构,即存在数据的从属关系。这时我们就必须把这种结构存入一个二维表结构中,按照上一段的解释就是我们的存储结构实际上是把树形节点作为一个数组存起来,每个节点都有自己的属性。我想前提条件说的差不多了。那么开始正文。
树形结构我们关注的是节点的关系。对于关系的存储这里给出三种方式。
一、简单的父子节点关系。
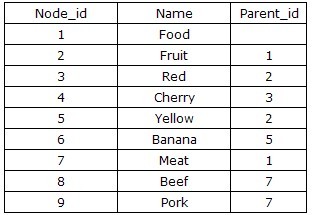
基本的父子继承关系。
这也是做容易想到结构,简单明了,一目了然。正是基于这种继承关系,我们可以向上找到父级,向下找到子级节点。并且在不排序的前提下实现查找和遍历操作(这个好像不算优点… …)。不同的设计思路是字节的id如图的Node_id设计为自增长保证唯一性,其持有的Parent_id于父节点的Node_id相对应。
但是其缺点也算是大部分属性结构查询的缺点吧,就是遍历起来麻烦,当然了这里的麻烦也是相对来说的。如果是查询一棵树出来就要不停的递归,这种递归在单SQL语句似乎难以实现,于是就不可避免的使用存储过程,现在比较靠谱的方法是使用临时表存储遍历获得整棵树的ID,然后查出所有ID对应的记录。当然了如果使用所谓的懒加载,即不展开子节点待点击展开时单独查询也是一种不错的选择。具体查询语句和存储过程在此就不多啰嗦。
二、基于Tree的遍历算法。
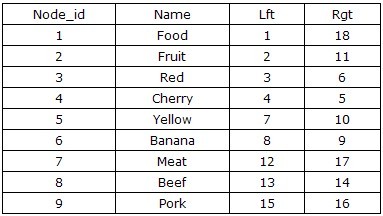
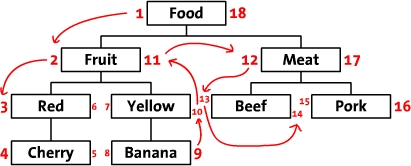
这算是一种比较高级的方法。使用树的前序遍历保存树形结构。左图为存储结构,有图为层次结构。对这个有兴趣的话可以看看这个文《Storing Hierarchical Data in a Database Article。依据此设计,我们可以得到一些有趣的内容,我们可以推断出所有左值大于2,并且右值小于11的节点都是Fruit的后续节点,整棵树的结构通过左值和右值存储了下来,这样你会发现他的好处,那就是方便查询和定位,避免了第一种的大规模遍历操作。但是也正如你所看到的,这种存储方式过于复杂,在做添加删除操作的时候几乎整棵树的节点都会变动,所以这种结构最适合那些常量类型或很少变更的树形结构。
三、基于分组的树形结构。
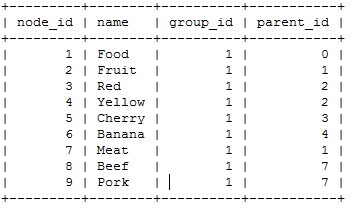
这种方式是本人最近想出来的,自然这种方式有一定的局限性,不过在特定的范围中使用还是很不错的。
场景如下,某个常量表存储若干类型数据,每种类型数据有自己的一棵树形结构,所以在这个表中存在若干颗树,也就相当于存在若干组数据,每组都为树形结构,最开始直接想到的第一种,感觉良好。后来以常量表为模板建立的基于树形的数据结构,也就是类型与常量表中的分组数据相对应,但是实际数据层次与常量表中不同的,即树的规模上不同。本来也可以使用第一种方式,但是鉴于此表存在大量的查询和变更操作越想越觉得递归和临时表的方式在将来可能存在性能上的问题。
于是冒着数据冗余的风险,我加了一个分组字段。分组的方式有很多种,在模板表中可以按照类型分组,这样直接使用类型就可以单纯的一条select语句就可以查出整棵树。而在数据经常变更的情况下无选择使用根节点ID作为分组ID。
这种结构有如下几种好处,如果你知道group_id,当然这个值可以是某些特殊属性。那么可以简单查询出整棵树,如果你获得某个节点,那么同样可以迅速查处这个节点所在的整棵树。同时特具备第一种情况的好处之外,还有一点就是,当你获得这棵树的任意一个节点的时候,你可以根据group_id和parent_id=0条件迅速找到这个可数的根。所以在node_id、group_id和parent_id的不同组合下会出现很多奇妙的现象。
接下来我想在第三种方法上继续扩充实现一些更加高级的功能,当然这是以后的事情。
———–我是境界的分割线————–
数据库设计是一项比较复杂的工作,因为他同时在抽象客观事物的时候还要兼顾到使用上,也就是编程的方便、甚至是扩展性。在数据库结构成型之后,又需要使用各种SQL技巧客服种种难题,这真是一场没完没了的战斗。
以上。