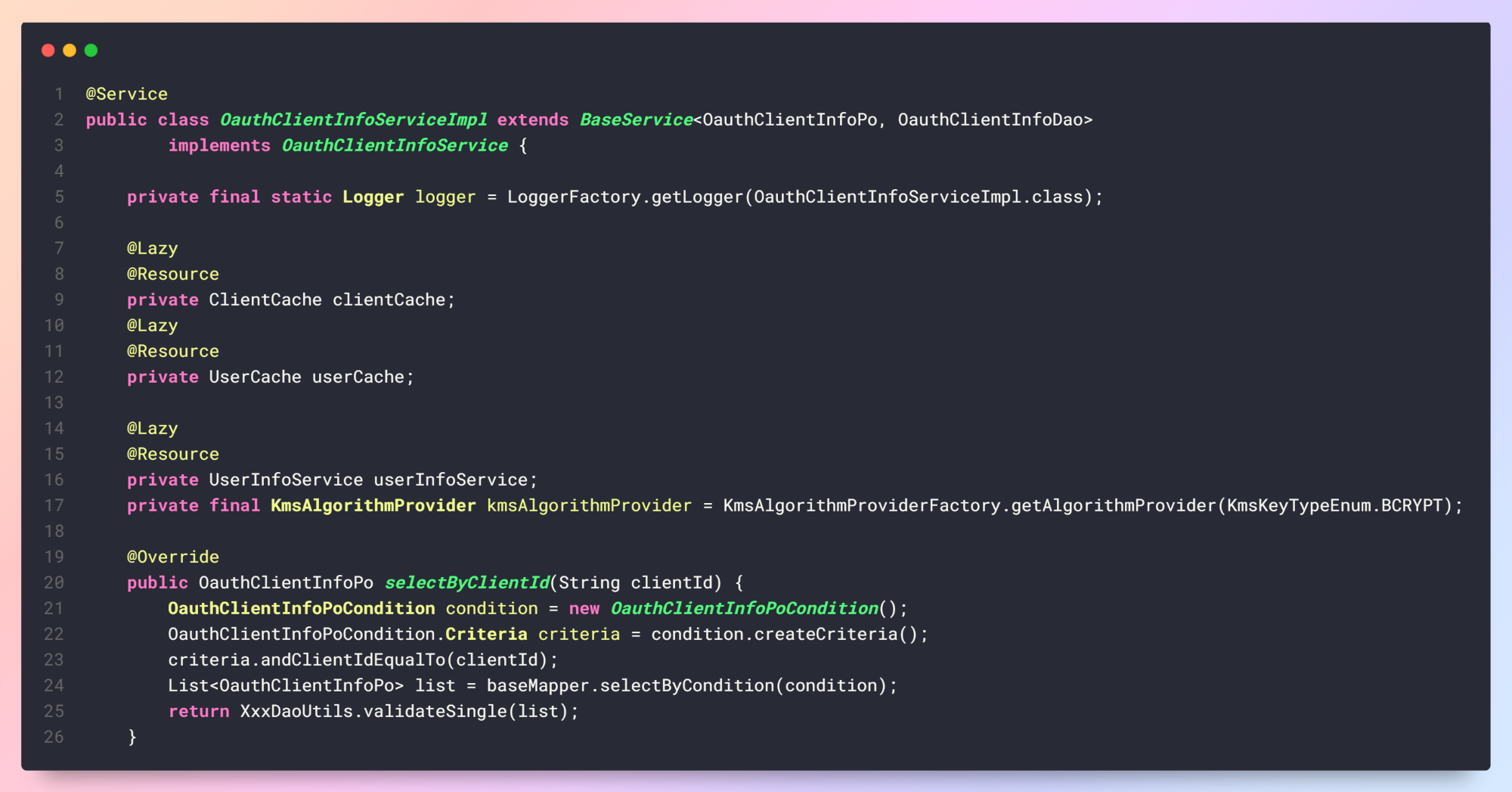
html文本解析类库jsoup
jsoup是一个html的开源解析器,正像我之前说的那样,这里的j指的是java。所谓解析html最常规的应用场景就是抓取某个html文本,然后获得其中的某个节点的内容(把html当做XML理解就好了)。java解析html的类库不在少数,但是在我接触的这么多开源库中个人觉得jsoup使用起来最为友好,最为简便。说其简便,那是因为它支持jQuery选择器语法。
jsoup是一个开源的java库,主页地址http://jsoup.org。这里简单的介绍下用法,现在有这样一个应用场景,在做apache监控的时候需要获得apache的server-status页面的内容,进而解析出html的内容。虽然apache的status提供了方便机器读取的auto页面,但是其毕竟很有限,如果需要获得连接的详细信息的话就只有抓取html页面进而解析出来。现在假定apache开启mod_status模块,并启用ExtendedStatus。
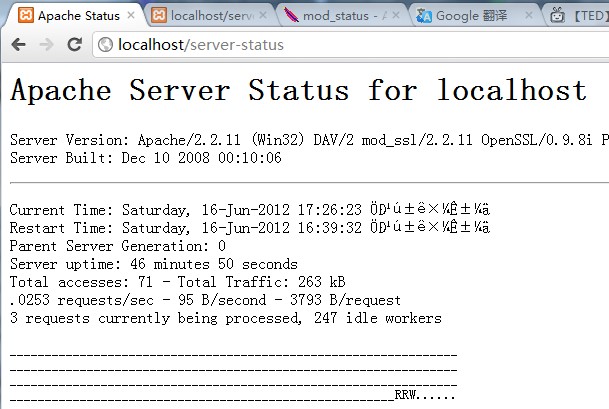
确认status模块可用,现在抓取连接信息,如下图的内容
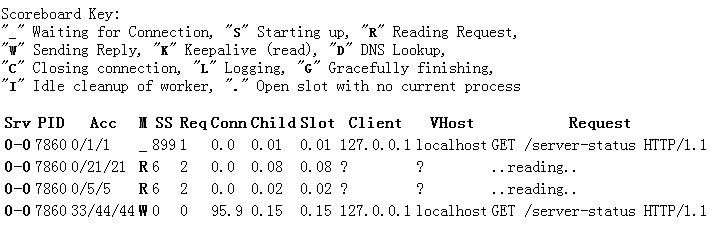
现在简单些,要获得每个连接的状态,也就是M列的_、R、W等信息。现在分析源代码。html文本的格式如下图所示:

可见这些内容实际是在一个table标签中,需要获得第一个table,然后找到每个tr标签,然后获得第四个td标签。知道了这些后代码就非常简单,如下图:
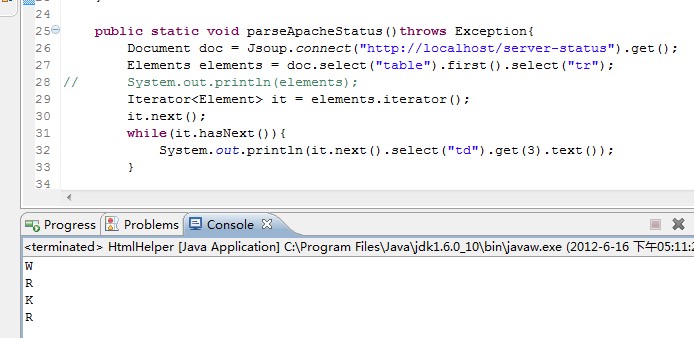
中规中矩,一次获得table,frist、tr、td[3]。现在终于到主题,那就是jsoup的选择器语法。官方详解地址:http://jsoup.org/cookbook/extracting-data/selector-syntax。但是有个问题需要知道,那就是虽然支持jQuery选择器语法,但是并不是任何jQuery的写法都支持,比如我选择第一个table是jQuery文档说可以这样写(table:first),但是jsoup就需要first()方法。
择器概要(Selector overview)
- Tagname:通过标签查找元素(例如:a)
- ns|tag:通过标签在命名空间查找元素,例如:fb|name查找fb:name元素
- #id:通过ID查找元素,例如#logo
- .class:通过类型名称查找元素,例如.masthead
- [attribute]:带有属性的元素,例如[href]
- [^attr]:带有名称前缀的元素,例如[^data-]查找HTML5带有数据集(dataset)属性的元素
- [attr=value]:带有属性值的元素,例如[width=500]
- [attr^=value],[attr$=value],[attr*=value]:包含属性且其值以value开头、结尾或包含value的元素,例如[href*=/path/]
- attr
=regex]:属性值满足正则表达式的元素,例如img[src=(?i).(png|jpe?g)] - :所有元素,例如
选择器组合方法
- el#id::带有ID的元素ID,例如div#logo
- el.class:带类型的元素,例如. div.masthead
- el[attr]:包含属性的元素,例如a[href]
- 任意组合:例如a[href].highlight
- ancestor child:继承自某祖(父)元素的子元素,例如.body p查找“body”块下的p元素
- parent > child:直接为父元素后代的子元素,例如: div.content > pf查找p元素,body > * 查找body元素的直系子元素
- siblingA + siblingB:查找由同级元素A前导的同级元素,例如div.head + div
- siblingA ~ siblingX:查找同级元素A前导的同级元素X例如h1 ~ p
- el, el, el:多个选择器组合,查找匹配任一选择器的唯一元素,例如div.masthead, div.logo
伪选择器(Pseudo selectors)
- :lt(n):查找索引值(即DOM树中相对于其父元素的位置)小于n的同级元素,例如td:lt(3)
- :gt(n):查找查找索引值大于n的同级元素,例如div p:gt(2)
- :eq(n) :查找索引值等于n的同级元素,例如form input:eq(1)
- :has(seletor):查找匹配选择器包含元素的元素,例如div:has(p)
- :not(selector):查找不匹配选择器的元素,例如div:not(.logo)
- :contains(text):查找包含给定文本的元素,大小写铭感,例如p:contains(jsoup)
- :containsOwn(text):查找直接包含给定文本的元素
- :matches(regex):查找其文本匹配指定的正则表达式的元素,例如div:matches((?i)login)
- :matchesOwn(regex):查找其自身文本匹配指定的正则表达式的元素
- 注意:上述伪选择器是0-基数的,亦即第一个元素索引值为0,第二个元素index为1等
既然都说出了API那么现在还远远不够。最原始的代码为
1 | Elements elements = doc.select(“table”).first().select(“tr”); |
但是呢这明显很丑陋,于是在看了API之后竟代码改进如下
1 | Elements elements = doc.select(“table tr td:eq(3)”); |
一个选择器实现选中table 下的tr中的所有第三个td元素,但是在第一个table处写:eq()等没有效果,不知道是什么原因,这个我还要再想想。运行结果截图就不贴出来了。就到这里了。