Index-TTS
因为工作中与目前所谓的比较广义的 AI 有一些交集,前一段时间偶然安静下来的时候回想起很多年前的一些关于未来的畅想,然后惊讶的发现,这其中的一些核心技术似乎已经实现了。
果然很多事情,换一个角度来看就会完全不一样,比如往科幻或者“中二”的方向思考。跨越这个不是很长的时间维度,顿时觉得似乎经历了很多不得了的事情。
回想起来第一个令我感到惊艳的是绘画领域的 Stable Diffusion 。经常关注一些画师,经常看到他们的作品,在某一天看到 Stable Diffusion 时感觉到似乎某些方面已经迈过了那个门槛。接着是伴随着 DeepSeek 横空出世,那些效果很不错的大模型突然来到了身边。在工作与学习中,无论是编码的实践还是需求与设计的广泛深入的探讨,这些大模型很好的指导了实践,完善与拓宽了思路与思想,节省了大量的时间。

在我以前的想法中,目前以大模型为代表的 AI 技术还处在两个极端的方向。日常使用中替代搜索引擎,然后专业领域辅助编码与设计工作。 就在前几天我了解了一下目前的 “整活” 视频,比如各种关于《凡人修仙传》二创的方法。无意中看到自媒体从业人员使用 comfyui 做图像、动作、声音的替换,然后突然意识到这些 AI 原来距离我们这么近。前几年还只能用 PR , AE 做视频,现在的大模型做出来的效果竟然这么好。我觉得不应该过于严肃的思考这些 AI ,而是在实际生活中当作一种普通与普遍的技术或工具来接纳他们。
于是我想到了前一段时间偶然看到的 Bilibili 开源的 index-tts(Github) 项目,准备先实践一下为某个没有配音的游戏加上多人语音。
1. Index-TTS 部署
这里不需要关注此模型的技术细节,初步的介绍与部署方式直接看官方的 README-zh 即可。以及官方的演示页面 IndexTTS2(Github) ,里面有非常只管的演示
简单来说这个 Index-TTS 与一般意义上那些固定机械音不同,而是使用提供的音源进行有感情的朗读,而且亮点就是可以设定情感上。这对于游戏多人文本朗读再合适不过了。
部署直接按照官方文档即可,其中也提到一些坑的存在,这里根据我的部署情况简单介绍一下。这里主要有三个方面。
- 大文件下载:
git lfs pull命令无法从 Github 仓库拉去音频文件,最简单直接的方法就是从 WEB 页面将/examples目录中的音频文件直接下载下来即可。 - uv 环境:我在安装时遇到一系列莫名其妙的情况,这里注意虚拟环境即可。
deepspeed安装:Windows环境中使用--extra webui安装而非--all-extras,全部安装时其中依赖的deepspeed在Windows环境下无法安装(试了几个小时最终放弃)。CUDA 12.8:最好使用 CUDA 12.8 ,在deepspeed无法安装时我升级到了12.8。不知道实际上有没有影响。- 代理:
HF_ENDPOINT、huggingface甚至有时候需要整个终端代理(速度问题)。
在 clone 完成后开始下载模型,huggingface 与 modelscope 皆可。这里使用 modelscope 。
使用 uv run webui.py 命令运行,在此期间必定需要从 huggingface 下载模型。注意访问速度或者使用 HF_ENDPOINT 分流(看官方文档)。
2. 使用
使用没什么多说的,效果与官方几乎一致。
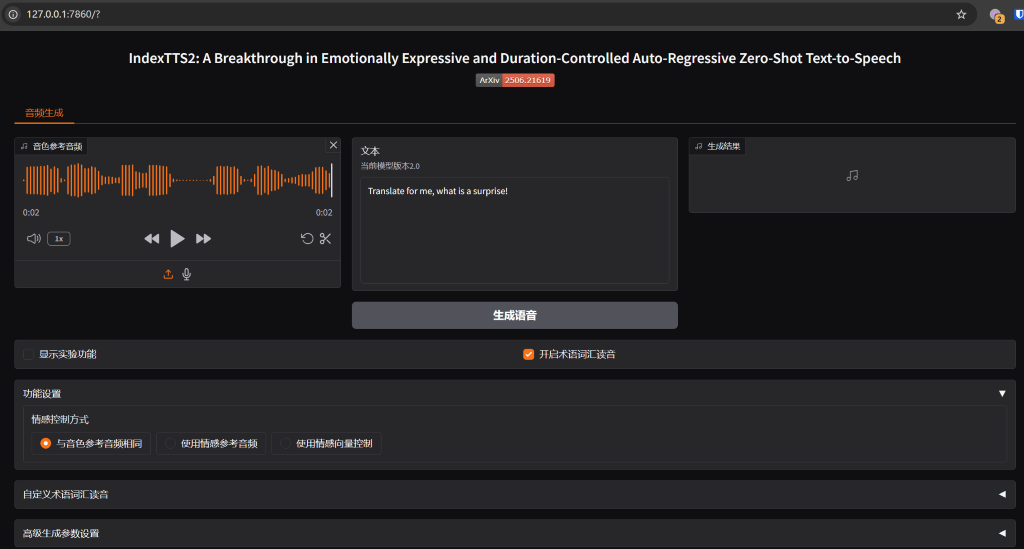
使用这个经典例子,“翻译翻译什么叫惊喜”。很不错。
然后关键的来了,我将游戏中语音作为音源,拿另外一段语音的文字合成,然后将合成的音频与官方语音进行对比。最终效果虽然还是有那么一些“痕迹”,不过已经完全超出了我的预期。终于能够分场景,多人物,有感情的朗读课文了(泪目)。
3. 资源使用
最后是关于资源使用的问题
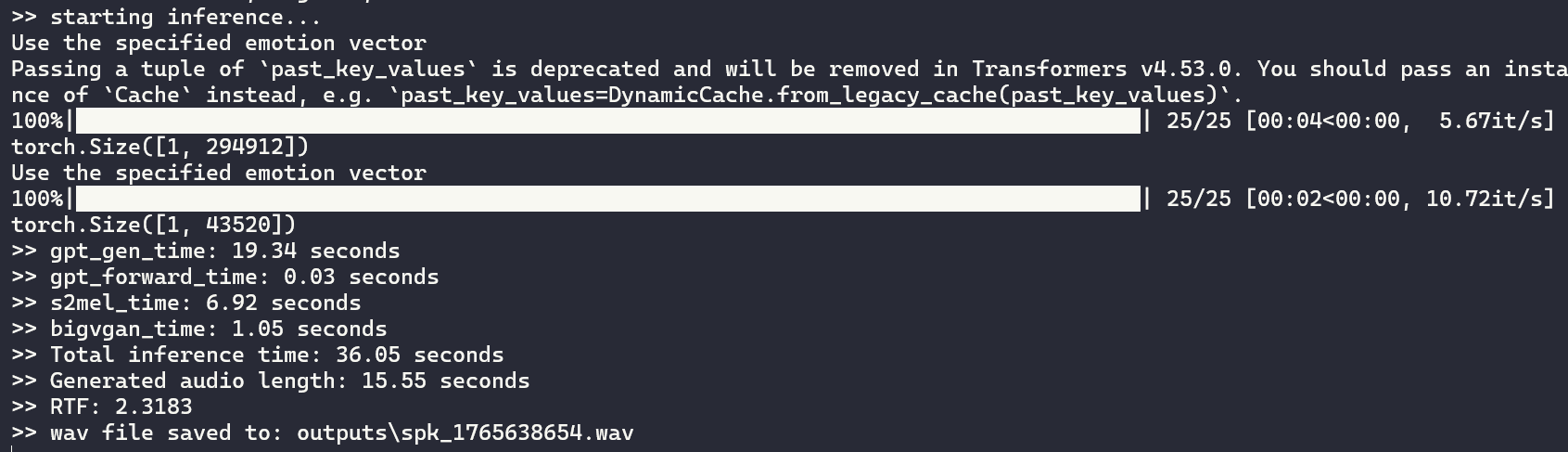
如上图,只是短短的 16 s 语音执行时间就有其长度几倍,长语音我在真正使用的时候再看看情况,随后补充。
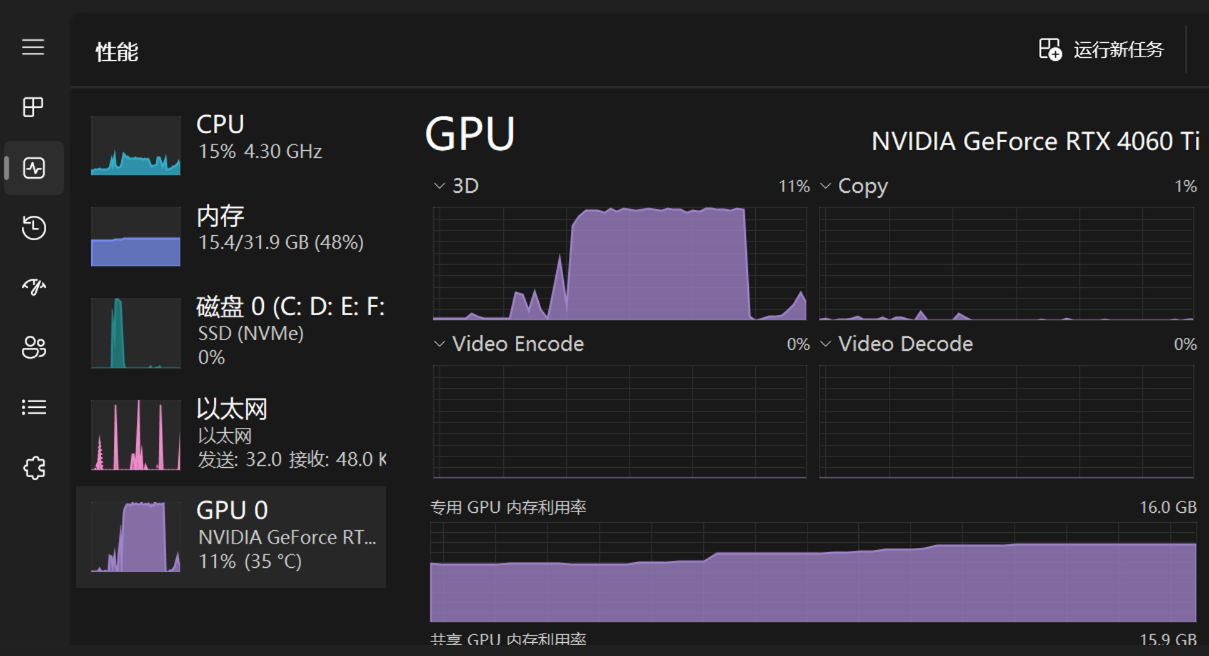
资源占用方面,现在使用这个入门级的 4060 Ti 勉强还可以用用, 8 G 显存感觉应该很吃力,不要浪费时间了。
完。