使用 Wiki.js 初步构建知识库

我个人一直困扰于个人知识的管理,包括一些静态资源,各种文本片段,以及总结输出的结构化内容。而这一切的目的就是在我需要的时候能快速找到它们。
经过深入的思考,以及做了一些尝试后发现,这个目标远比我想象中的复杂好多。于是我决定将要求放低一些,以 wiki 的方式对知识进行管理。在对比了一圈后发现,非常轻量化的 wiki.js 满足我的需求,于是从 Github 把代码拉下来尝试了一下。
TL;DR点击列表跳转
1. 知识库构想
对于自己的知识库,初步设计了一个满足通用场景的是数据库,又参考了一些开源 wiki 的数据库设计。之后发现我i的想法和很多系统实际上有较大区别。
在我设计的系统中实体信息分为如下几个维度
- 材料:(暂定名),是一些不归类于业务的数据,包括直接引用的文件,图片等。最直观的体现就是一篇文章中临时上传的图片,这类数据全部在业务上无法管理。
- 资源:最小可管理业务数据。从一个文档,到一副图片,以及一个社交网络账号信息。资源级别也是最灵活的组成方式,根据组织方式不同可以实现不同的实际业务需求。如账号信息可以根据层级关系,实现一个社交网络卡片用于展示某个用户在不同平台的信息。资源存在内部引用和外部引用。
- 片段:(暂定)这个存在于构想阶段,原因是这个层级还没有找到共性。
- 知识:这是最终可用的结构化资源数据,最直观的体现就是一篇文章。是经过总结消化再输出的富文本内容。其本身也存在内部引用和外部引用。
对于日常使用,最多的是“知识层级”。因为在工作学习中遇到问题需要快速定位到对应的“知识”,而不是想了半天觉得似乎之前在什么地方看过,最终变成求助于搜索引擎。不仅浪费时间,更关键的是这些可能没有验证过的信息存在很大的不确定性。
而资源类数据其实是无法直接使用的,这里以账号类资源为例。比如今天我想看看某个画师大佬最近有没有新作,那么我先找到他的社交卡片,从卡片找到其在各个平台的地址,如 Pixiv 或 twitter ,然后跳转过去。或者再直接一些,通过查社交卡片找到关联的各个平台账号。并将这个账号集合当作查询条件,从图片资源库中查找。当然这个资源库就依赖于爬虫了。

这里说的卡片是类似于Carrd 提供的,感觉比较小众但是非常实用的功能。如上图,当然也有其他的卡片服务,不过 Carrd 这个名字辨识度太高,就记住了。对于社交卡片的应用再引申到机构账号(如游戏官方),那么在需要对应到中文社交网站主页,中文视频网站主页,推特中,日,英等账号。此外还要关联相关的 meme,bot,news类的专门账号上。如果再辅助以爬虫功能,那么几乎能看到所有相关信息了。
1.1 输入输出分离
在我设计出几个版本的数据库后,思考输入与输出分离的构建方式。
简单说就是将文本内容直接渲染成静态文件,由 ngnix 一类的入口直接返回,不直接请求应用服务器。在确定了这个方向后仿佛一切都简单了很多,因为文本编辑和展示可以完全分离了。
- 输入系统:使用 obsidian + Git 的方式,甚至将文件托管到开源代码平台。这样就可将自己服务器上的同步服务和客户端的同步软件全删掉了。一下子神清气爽了。
- 输出系统:使用 wiki 系统做文章类内容的展示。资源类数据由于和爬虫系统挂钩,以及 wiki 系统到底如何使用还没有想好,所以资源类数据还是要自己实现。不过资源数据不是现在急需的,我要的是在PC,移动端浏览器快速找我总结的知识。
这样的设计的好处是什么呢?之前的想法是输入系统与输出系统都使用笔记类软件。在弃用了几个收费软件后,最大的问题就是软件跨平台,以及数据同步。而在分离后输入就安心在我自己的电脑上进行,上面有各种开发所需软件,再加上 GIT 值得信赖的文件对比。使用的时候只需要一个浏览器即可。
1.2 Wiki
wiki 系统我的总结大致分类两类:
- mediaWiki 类:这是我们直接接触的通用 wiki 平台,如百科类 wiki,游戏 Wiki。我在看了几个开源 wiki 的文档以及数据库设计后觉得,首先功能过于大而全,与自己的系统设计存在冲突,后续无法整合进自己的系统。以及与我 markdown 的原始文本存在渲染转换问题。就像我使用 obsidian 一样也是点到为止,不会过度依赖其自身的特有语法以及插件系统。
- 文档类:这类说是 wiki ,其实更多的是文档类网站。如很多开源项目自己的介绍站点和API站点,如 MkDocs。在看了它的文档后我觉得这就是我理想中的技术文档系统,再加上 material 主题我简直的太喜欢了。
mkdocs 毕竟是文档站点,做 wiki 站还是不太合适。之后我找到了 java 开发的 xwiki ,想看看代码二次开发。但是在看到打包好的文件,lib里面能翻好几页的 jar 文件,Github上也是一眼看不完的包名。头疼。于是我找到了 wiki.js 。
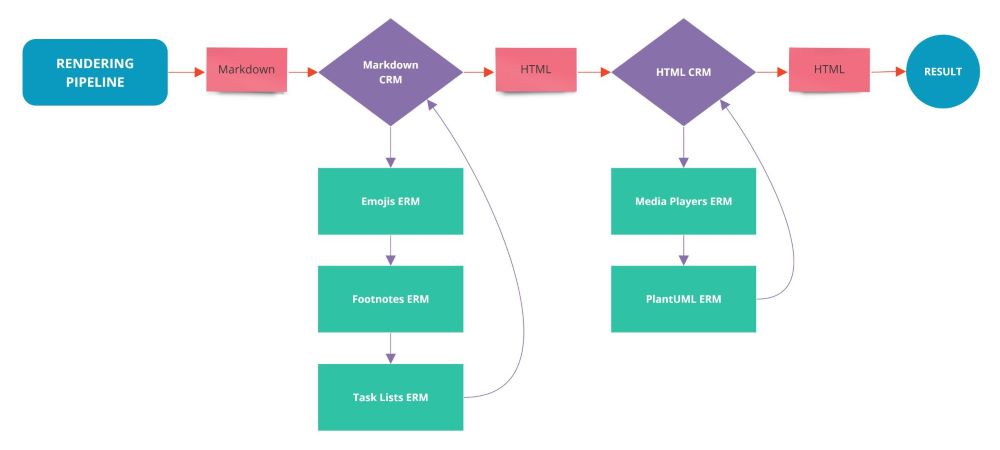
2. Wiki.js
2.1 快速开始
Wiki.js 正是由于其有我所需的基本功能,再加上足够简单。在仔细看来文档后,我就用这个了。
直接进入正题
- 官方文档 : https://docs.requarks.io/ ,这个文档站点本身就使用 wiki.js 搭建,在看文档的时候也能直观的感受一下。
- 下载发布版本:https://github.com/requarks/wiki/releases 。
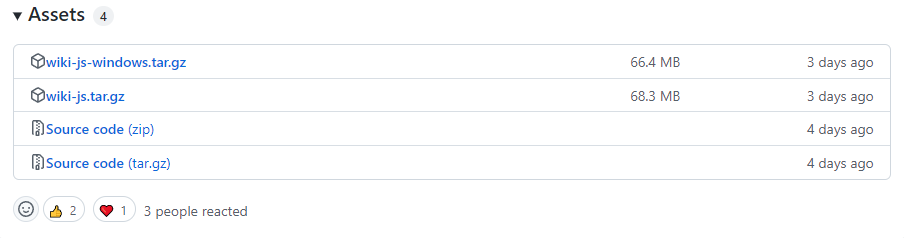
直接下载 wiki-js-windows.tar.gz 。解压文件后将目录下的 config.sample.yml 拷贝一份 config.yml ,并修改其中的数据库信息。
确保安装了nodeJs ,在解压后的目录运行 node server。
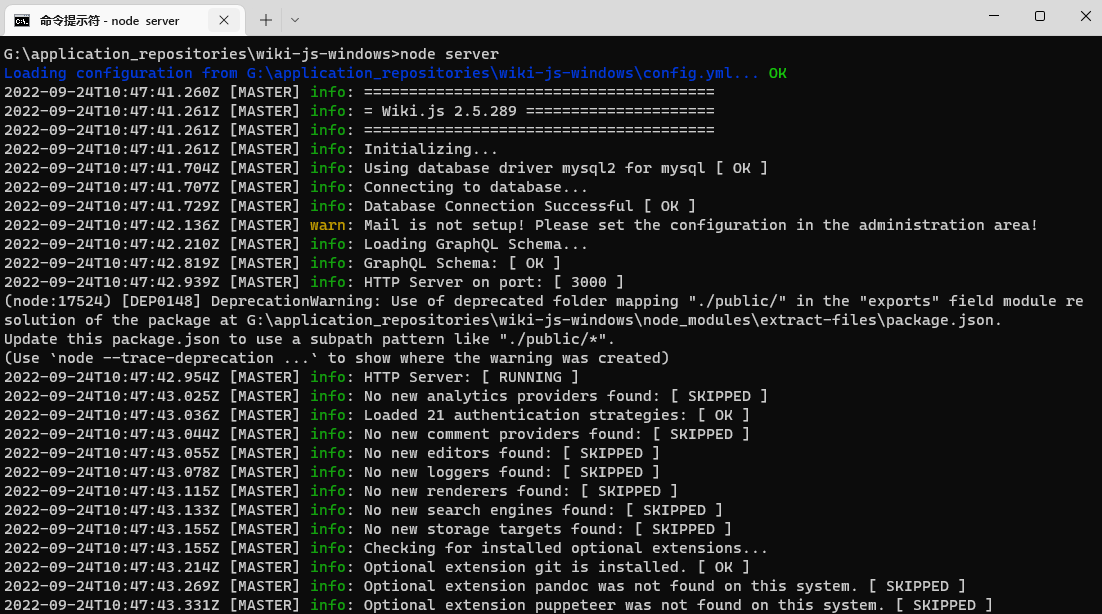
很快的启动了起来。然后打开数据库,一眼看到 pages 这张表。
1 | CREATE TABLE `pages` ( |
瞄了一下表结构,可以看到文件原文存储在 content 字段,渲染后的文本存储在 render 字段,文章目录(TOC)以JSON的方式存储在 toc 字段中。
进入后台改下语言,设置下杂七杂八的东西。然后就看了看渲染系统和API系统,当然还有同步系统,在没搞懂这个同步什么流程前,反而对这个 API 访问以及 GraphQL 更感兴趣。
2.2 虚拟文件夹
2.2.1 目录切换
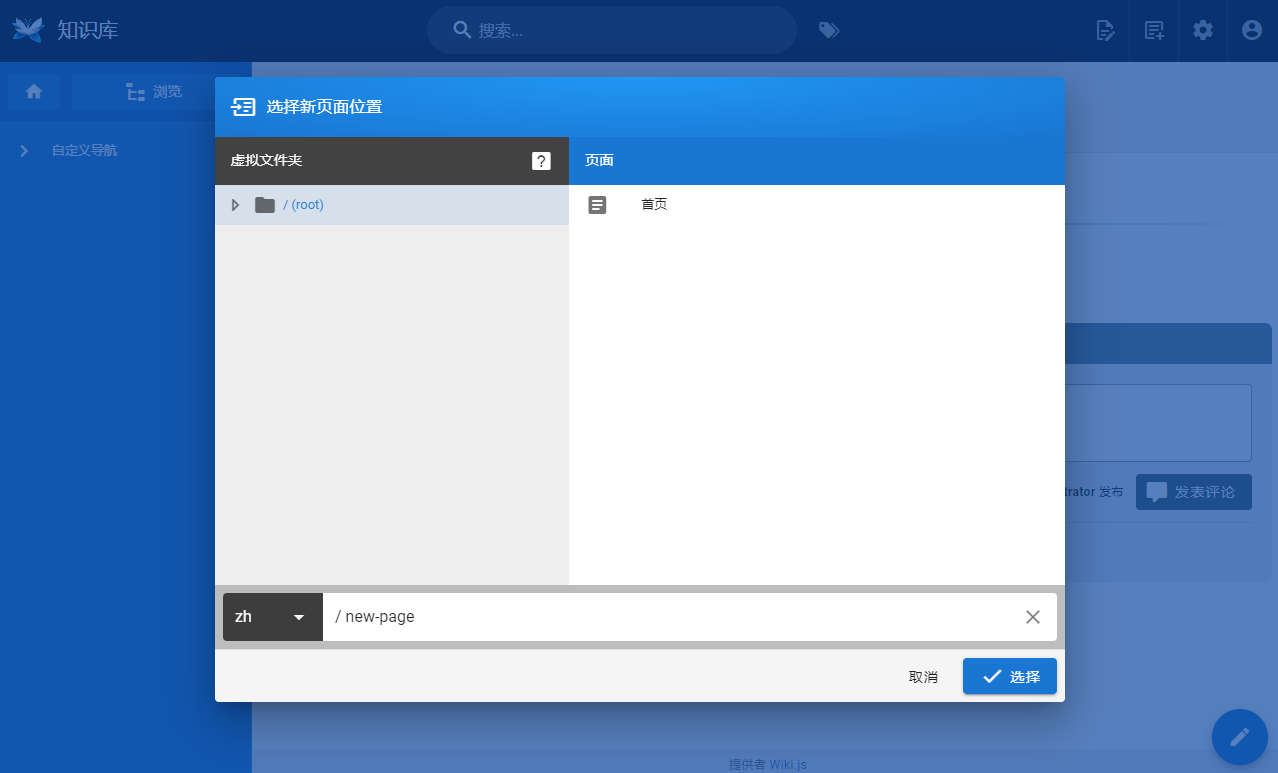
在切换到这个前端页面后点击右上角的 创建新页面 链接,弹出新建页面的位置选择对话框。这里的虚拟文件夹选项,我认为是这个系统给我的有一个眼前一亮的地方。
- 虚拟文件夹可以看作目录结构:在下面的输入框中输入 URL 路径的形式,注意不能以斜杠结尾,因为最后一段路径就是当前的文件名。注意这个文件名至关重要。
- 这个虚拟文件夹是不存在的:这个值存储在
pages表当中,系统并不会维护这个树形目录结构。这个路径会在系统启动后计算出目录树并缓存起来,当你点击者面包屑的时候,会根据这个地址匹配pages表中的path字段。所以当你点击中间节点时系统会提示页面不存在。
我认为这个虚拟目录的设计非常的灵活,因为文本就是存储在数据库中的,维护一个目录关系也没有意义。但是毕竟虚拟目录和真实目录是存在区别的,即不能存在空目录。所以在书写的时候必须存在一个类型于 index.html 的目录默认文件,在转换到 wiki.js 系统后当作当前目录节点的默认文件。
后来又测试一下,发现导航栏只是在做页面切换,而面包屑是真的在切换目录对应的文件。
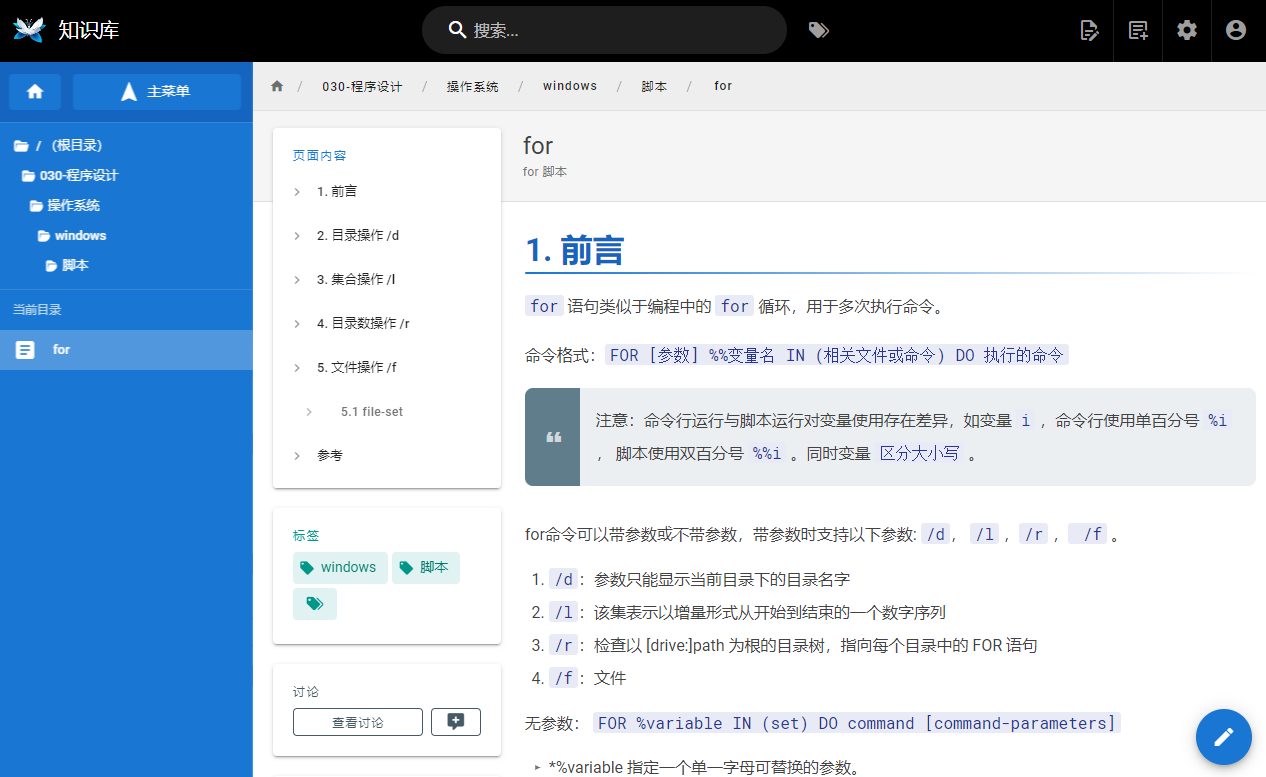
这里我直接进行一个试的测,在一个较深的目录下新建一个 markdown 文件。这时候左侧的导航树由于是目录树结构,可以任意却换目录结构。但是文章正文上的面包屑除了末端节点外都不能点击,因为系统去找相应的文章正文,而不是进行目录切换。
2.2.2 排序
在我意识到虚拟文件夹存在问题后,想到可能存在排序问题。在文章页面设置以及后台找了一圈后,又看了看数据库发现似乎没有地方存储排序信息。
那么其实也好办,又减少了 obsidian 到 wiki.js 的转换工作。简单来说与 obsidian 一样排序依赖于文件名升序,那么就像 obsidian 一样,在所需目录以及文章路径上增加数字前缀。

如上图所示,按照 obsidian 的目录组织与排序方式直接迁移过来。
同时虚拟目录的好处还有,任意调整目录结构是不影响数据存储和文件存储的。只是不知道当页面较多时性能如何,不过个人使用应该是足够了吧。同时这类站点几乎都是后端模板渲染,体现出来就是请求页面会全局刷新,也就是非异步请求。不过话又说回来了,如果把页面静态化又会牵扯到更多问题,每每想到都感觉头痛。
2.3 功能
说实话这个 wiki.js 的功能确实够少(笑),不过这也正好符合我的使用习惯。那就是简洁并且功能足够的导航,搜索,以及最关键的页面展示。
双导航模式
其实 wiki.js 在编写模式下存在两种模式,从这点上看反而更像是文档站点的设计思路。
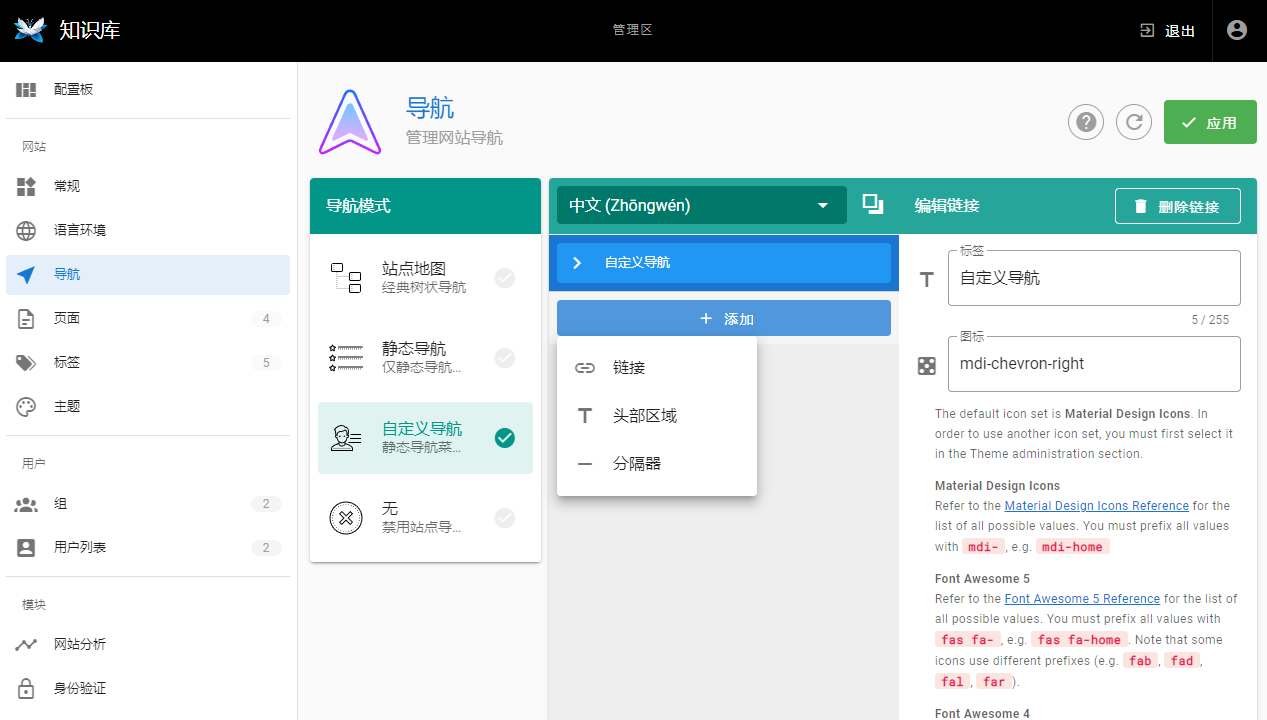
- 菜单模式:菜单模式可以在管理后端称为导航,也就是自定义的快速访问地址。可以是系统内页面,也可以是外部链接。
- 浏览模式:浏览模式就是虚拟目录组成的目录树,包含系统所有的页面链接。
当然菜单提供了,站点地图,静态导航,自定义导航,无,四种模式。试了试个人比较喜欢“自定义导航” 这种,也就是一个自定义链接菜单,一个全页面的路径结构。
搜索
搜索在一个 wiki 系统里是属于非常重要的功能,初步测试默认是数据库搜索方式,似乎之只支持标题和路径搜索
1 | Supported Database Engines: |
由于我使用的是 mysql 5.7 ,总是在管理后台提示数据库版本太低,部分功能受限。不知道版本提高了是不是支持全文索引。
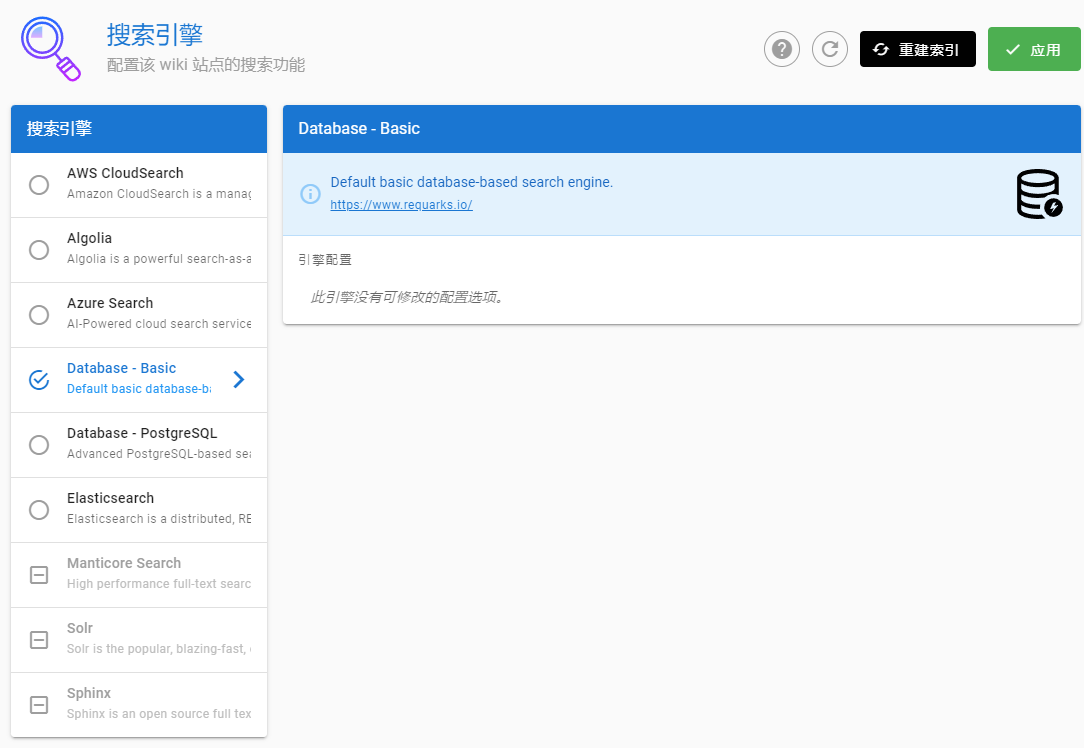
看到后台设置是支持外部搜索引擎的,毕竟数据库做全文搜索还是有极限的,不如交给支持分析的搜索引擎吧。哎,文档也没写清楚,看来最终还是要去看代码才行。
最后是渲染和标签管理了。渲染的问题在于主题系统没做完,所以也没有三方主题。不过默认的我已经很满意了,但是例行的先将行间距调整为 2.0 。后续可能要调一下表格,以及不同级别的标题的边距。目前就足够用了。
而标签系统,可以直接将 obsidian 的标签系统转换过来,很棒。接下来最大的问题就是看看 wiki.js 的 API 以及 GraphQL 到底支持什么功能,以便定期同步 obsidian 的文件过来。
OK,接着折腾吧。