项目文本处理选型

这里需要构建一套文本处理系统,当然了构建系统从来就不是一蹴而就的,必须要面对客观环境与实际的需求,系统将来是什么样这谁也不敢保证。但是系统本身就是对客观与现实世界的抽象与归纳,对于系统的构建和设计从一开始又不能拘泥于当前环境。总是说了那么多就一句话,功能可以没有,但是设计一定要到位。
这里简单介绍一下我的选型路线,包括前端和后端,移动端目前又处在一个选择的路口。因为Flutter2的发布,以及明确的跨平台方向。桌面是否有能力挑战 Electron 这是我非常关心的,不可否认的是Electron是现在开发桌面应用的首选了,但是我对其运行方式一直不是很满意,因为大量的基于其开发的PC软件给我非常不好的使用体验,包括印象笔记,和大量的PC端音乐播放软件,这里特别要说网易云,最近的它的启动似乎越来越慢了。移动端在熟悉Flutter2前,先用响应式前端凑凑数。
那么基础的技术选型来说,前端 Vue/element-ui ,后端 Java 为主(可能会引入一些 NodeJS 或 Python ),数据库 mysql 做系统级支撑,如果有一些性能或业务要求那么就必须要文档数据库。文本处理方面NLP是不可避免的,但是对过于复杂的算法应用或机器学习暂时不做深入探究,同时大数据方面当前节点也不做探究。当前的目的是小而美,能支持基础业务。
这个系统在用户看来可以是一个在线记事本,一个笔记系统,一个团队文档协作系统,以及知识挖掘系统等等,从后端来反而更加清晰,它就是一个文本处理系统,包括NLP相关的分词,关键词提取,正文提取,生成摘要。以及相对似乎很高端的文本推荐与分类系统。
TL;DR点击列表跳转
1. 开源环境
不知道是从19年末还是20年初,我切身感受到开源环境有了非常大的变化,而且这种势头还在持续升温。
一开始我注意到很多卖课的机构开始做所谓的开源,这些开源作为系统的入门还是可以的,然后课程里面做深入讲解。随后出现了基础开源,付费升级维护与二次开发的项目,这部分可能是几个人,或者是小工作室。把自己的方案拿出来开源,并提供企业版或者说Pro版的付费内容。再之后出现了以企业的名义开源的解决方案,非常的全面。到目前为止这些项目更多的是所谓的微服务,很多技术都是相对来说比较“时髦”非常的吸引人。这确实为我们提供了不同技术方案与选型的完整实施效果,对于没接触过的人来说确实是难得的学习机会,对于有开发经历的人来说,他们提供了一套与工作环境中选型相对保守技术栈差别很大的框架与环境。这种环境最重要的是一套方案,让你能真正的看到这些技术与方案在整个系统中起到的作用。这些是在工作环境中很难接触到的。
上面这些系统与完整的方案,我一开始还认为是做推广,相当于先体验再付费。这对很多小薇企业来说其实是非常必要的,他们本身几乎没有开发甚至是没有技术人员,完全没有IT技术设施的建设。他们拿到项目或者付很少的钱就能先用起来。等业务壮大了再投资做定制甚至是组建自己的IT部门做自研。之后我看到很多非常传统的企业以及一些非常“传统”的系统竟然选择开源,让我不能理解。
这些一不留意又说的有点多了,我想表达的是在目前的开源环境下,对于整体和细节的技术选型我们有了很多实实在在,无论是方案级别还是代码界别的参考。减少大量的调研和实际测试的时间。以文档为载体的技术说明说实话对于某些特殊领域和特殊场景,对于没有实际或特定开发经验的人来说完全是毫无意义。当代的开源方式特别是以git和Markdown为载体的可web展示的直观系统,能让开发人员避免被文档花哨的架构图和某些领域特殊的专业术语带着绕圈子。很多时候如果项目按照规范来,那么我们可以迅速在代码层面定位到我们感兴趣的功能点。不过本来工程问题是一种由下而上总结归纳的东西,而现在的开源项目很多都陷入了知识点与大量技术点的堆砌。如果对于有开发经验熟练了解行业方案的“老鸟”还好说,而对经验不足或是想自学一些工作以外的知识的人,先不说开源项目质量如何上来就是大理论大知识面对海量存储,海量并发之类的搞的人云里雾里。这一点在Java领域愈演愈烈,打开项目看到十几个子模块都要以微服务方式发布运行,看起来花里胡哨但是分析过后还是那些换汤不换药的东西。更多时候更像是demo而不是可用项目,原因就是你方案铺那么大结果还是做些基本功能,整个系统就不足以支撑说的那些噱头。
我想这也就是那些细分行业或公司级项目开源的因素吧,这些项目相对来说非常灵活可按需选择功能模块和部署,并且经受过一定的生产环境的验证。同时由于自己就是行业用户,他们对于使用者的二次开发,付费支持有非常实际的经验,甚至能提供业务和需求方面的支持。
1.1 功能选型
功能选型是个很实际的问题,仅仅从一个功能上说很多时候不仅仅是技术问题了。更多的是要评估其在系统中的地位与作用,并且符合当前的系统规模,也是要避免“一步到位”为了是实现一个小功能就上线一个大系统。
这里可以粗暴的分为以下几种情况,当然可能有不少吐槽成分,因为很多时候在产品后面的开发对过来的需求是很难有个明确的把握的,所以大部分时候开发做功能是面向测试的。对方向的不准确把握很可能在未来的多次迭代中将问题积累下来,最终可能造成一个完全可以避免的大型重构。所以我很推崇DDD原则,将需求与功能准确的传递给开发。
- 能用就行:大多数是可有可无的功能,可能是谁顺便提了一下,也或者是开发人员想发挥一下。这种时候能少做就要少做,不要引入大型第三发框架或系统,不要把需求扩大化。
- 做个功能:明确要求要做个功能。这是大部分时间面临的问题,但是这也是最困难的,尤其是那些无法控制功能边界的管理人员,当然还不包括产品的需求变更。这种时候开发实际上就是面向测试,压力最大的反而是技术管理和项目管理人员。在则个阶段就要考虑功能的抽象和封装了。
- 实现一个需求:这个时候就要看技术管理的能力了,要做需求细化和拆分并安排开发去做。当然了厉害的产品很多直接就传达给开发了,而更多时候开发并不知道要做什么以及怎么做,这时就要做调研做评审。
- 做一个系统:这可能是对项目组甚至是部门要求了,可能是从无到有或者调动与协调资源做一个新的项目。这种场景才是在各种软件开发书籍与规范锁指导的领域,从远古的瀑布到现在的敏捷从整体上保障系统能最终落地。
- 要做最好:这个其实更多的是竞品分析了,要做竞争对手以及整个行业最好的。从技术的角度来说实际上已经不是一个层面的东西,要求可能是要做比市场上现有产品要好,比全球TOP的开源项目更厉害的功能。上面几种是用开源和理解开源,这种是重新造一个项目并且是最好的。
现在的好处是已经有大量的优秀的开源项目,我们可以充分的学习和借鉴。如果理解足够深又可以参与进去或者重启一个新的开源项目,这对于开发来说也算是非常大的荣誉了(笑)。
上面这些并不是经过严格思考的规范,也不是什么软件开发准则,只是感性的归纳,不要当真(笑)。
2. 前端
说是前段暂时只考虑WEB端。
前端对于实际开发来说如果是相对来说的大型项目那么必须要有框架级别的东西,从零开始做样式、脚本、工具链各方面的考量一般来说都是不实际的。在 JQuery 主导的时代这些选择非常有限,直到第一次做混合开发时看到 Framework7。说实话对于操作如此丝滑UI效果如此惊艳的开源 UI 库我是非常震惊的,所以当时项目第一个版本混合开发的 UI 层就是了 Vue 版的 Framework7。在往后的移动端混合开发实际上更多时候用的是 RN ,对于 React 选型 JSX 其实没什么问题,但是我对 Vue 的条件渲染非常的喜欢,相比 React能大大减少代码量。也不知道是不是我个人的问题,当我写React的时候实际上是把它当做后端代码规划的。先做功能设计,在进行代码抽象和封装,React 的组件我写了好几层继承关系封装了大量的公共组件。而 Vue 这边我根本就没往这边想,设计也是以文件作为基本单位。
这次选型的时候我也考虑过移动端和桌面的问题,在Flutter2刚发布我还处于观望阶段的时候我又去看了下 Electron。然后莫名的看到了Quasar Framework,说实话初看没有Framework7那种惊艳的感觉,但是我看了他的文档以及几个应用后非常吃惊,然后立刻去把所有控件的文档和demo看了一遍。

看完后觉得从文档来说控件的功能非常强大,自带的样式定制化也非常强。更重要的是除了table之外其他所有组件几乎都做了全平台适配·,这对于习惯了element和ant后觉得很不可思议。不过这些组件有明显的material design风格,也许是为了做全平台适配反而牺牲了PC端特有的一些强大组件,比如多级级联选择,多级可编辑表格等,这在一些场景几乎是不可替代的。所以说做一些互联网级别小而美的强体验UI确实不错,但是做一些重量级行业应用可能做定制的就非常多了。
对于文本处理来说前端的编辑器是必须有的,而编辑器在目前又分为Markdown和富文本。虽然对于技术人员来说Markdown是不看或缺的,但是富文本编辑器一直是难点,尤其是现在很多真的文档编辑方案,如石墨文档和几个大厂的产品一下子拔高了WEB端富文本编辑器的高度。这个高度是从用户使用体验,UI样式,团队协作全方位的提高。一些老牌的编辑比如UEEditor和CKEditor在企业办公场合还可以,但是在互联网环境下真的很难让用户提起兴趣。那么就先说一下富文本编辑器
2.1 富文本编辑器
首先一些老牌的编辑器如UEEditor和CKEditor这里就不介绍了,从技术层面来说大致有如下的发展轨迹
CKEditor 1-4(2008) -> UEditor (2012) -> Quill.js(2012) -> CKEditor 5(2014)
-> Prosemirror(2015)-> Draft.js(2015)–>Slate(2016)
这个发展大致为原始DOM派,到DOM抽象派,以及一些逆天到完全自己实现工具。
2.1.1快捷好用
观感很不错,用起来也比较顺手,如果仅仅是在为了原文展示而输入富文本的场景下,这些已经项目已经非常优秀了。
wangEditor、TinyMCE、MediumEditor、Pell、Simditor

但是论好感我更喜欢MediumEditor,毕竟我对medium这个网站有非常深刻的印象。不过话又说回来了很多时候技术只是一个选择条件,因为要考虑系统的定位以及用户的定位,medium这种在风格更加2C更加互联网化。
2.1.2 高级
相对高级一些的主要在于定制化开发,这里有
Quill Rich Text Editor、Draft.js、Slate
这其中,在不考虑团队协作的前提下,我首推Quill。原因很简单因为其可定制性太强了,在已有框架下通过JSON传参就能做到很多常用定制,再通过CSS定制就能实现很多类似于现在非常漂亮的编辑器,比如石墨文档。
2.1.3 团队协作
etherpad-lite(GitHub),以及官方网站Etherpad。
Etherpad 在09年被谷歌收购后开源,原本是有 Scala 编写,现在的 Lite 版是 NodeJS 重写。etherpad 并不是一个简单的前端编辑器,而是一个前后端都有的方案,如果搭建环境后端还要配置Mysql做存储。在看过其功能介绍和插件后,这种项目天然的让人觉得技术难度可能比较高。同时如果项目使用肯定不能直接拿来用,无论是UI调整、功能变更或者性能优化,这一系列的东西就让人头大。
具体的环境搭建参考 WIki
另外这种多人协作的场景在考虑版本管理的同时,离线存储也是不得不考虑的问题。所以也许会使用 PouchDB 与 Couchdb 的组合,那么可能就不是简单的修改开源项目的问题了。
2.1.4 文档编辑
上面说的富文本编辑,在对应的办公场景本质上对表的就是Word,同样还有不可避免的有Excel场景。
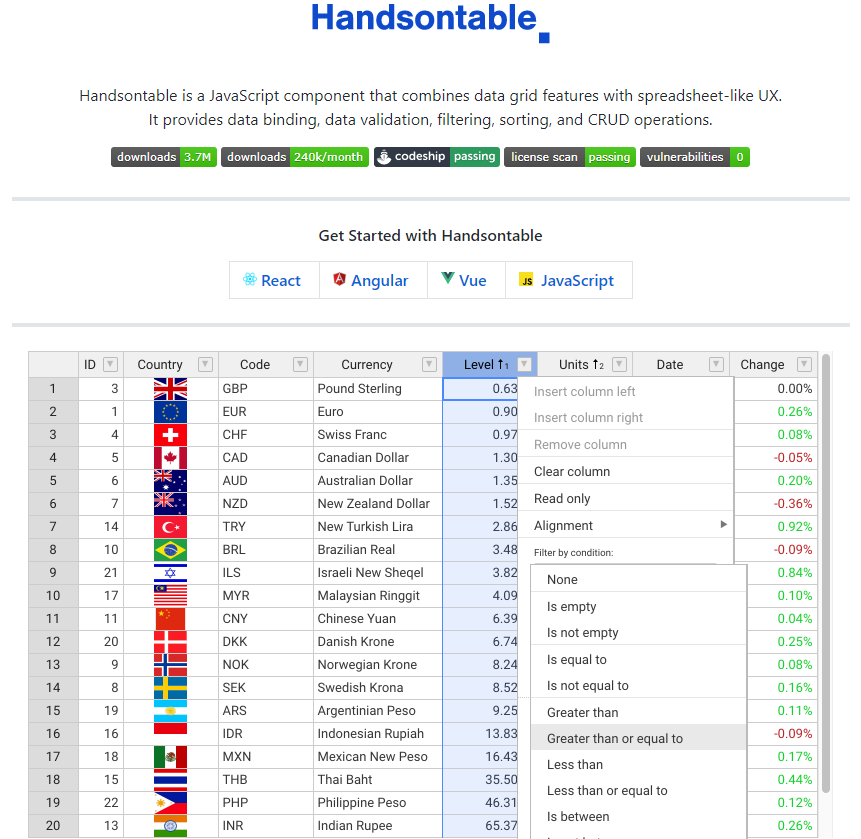
Web端的表格处理首推神级的 Handsontable,对我这样的前端出击爱好者当我看到浏览器里能做出类似于 Excel 的东西我是相当吃惊的。最开始看到Google有这种东西还可以接受,觉得这种大厂有些黑科技可以理解。直到我发现 Handsontable 这种开源项目,看到这完全的纯 JS 实现给我带来了巨大的冲击。
2.2 Markdown 编辑器
一般意义上的Markdown实际上就是一个纯文本输入框,再加上一个富文本渲染框。很多 Vue 封装过的 Markdown 编辑以已经可以满足大部分需求,很多拆箱即用的前端脚手架都集成的有在这里就不多说了,这里只说一下基于 Symphony 项目的社区 链滴,以及衍生而来的Vditor、markdown-online-editor 和 思源笔记
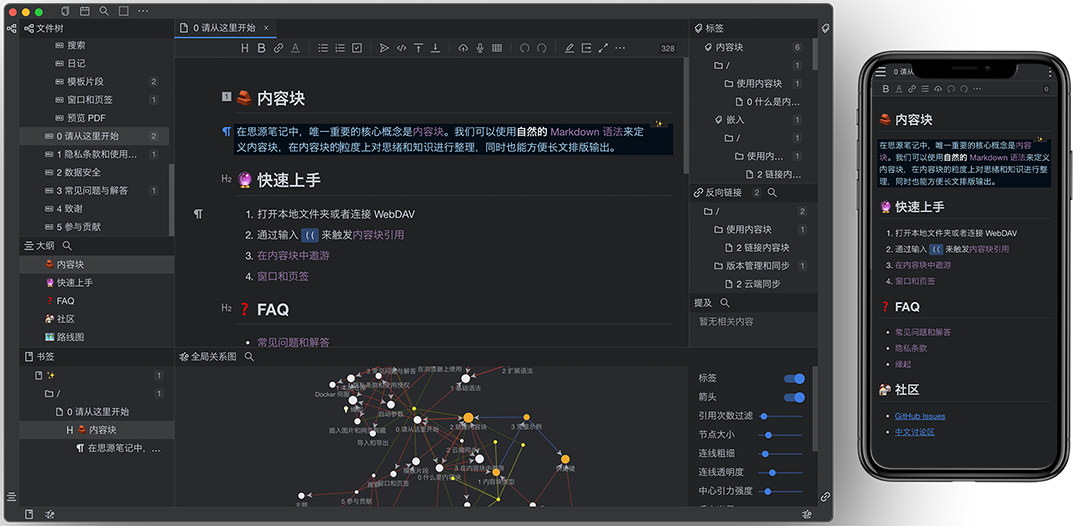
首先Symphony作为一个开源的社区系统,独立开发出了Markdown编辑器Vditor,进而衍生出了markdown-online-editor。最终在 Vditor 和 lute 的基础上衍生出了 思源笔记(Web)、思源笔记(GitHub)。
第一次看到思源笔记我是非常吃惊的,它几乎做出了一些备受好评的笔记系统应用有的功能。漂亮的所见即所得,块级引用、双链网状结构,思维导图等等。
Markdown正是由于非常受开发者喜爱,某种程度也算是一款代码编辑器的。而专门的代码编辑器如 VS Code 在线版国内我也只看到过华为的修改版,相对提供基础功能的 CodeMirror 倒是衍生出大量优秀的编辑器(这个项目还得到了JetBrains)。这还不包括 JetBrains Projector 这种让人理解不能的 JVM 向浏览器发送渲染指令,用 HTML5 Canvas实现的远程编辑器。
2.3 静态文档系统
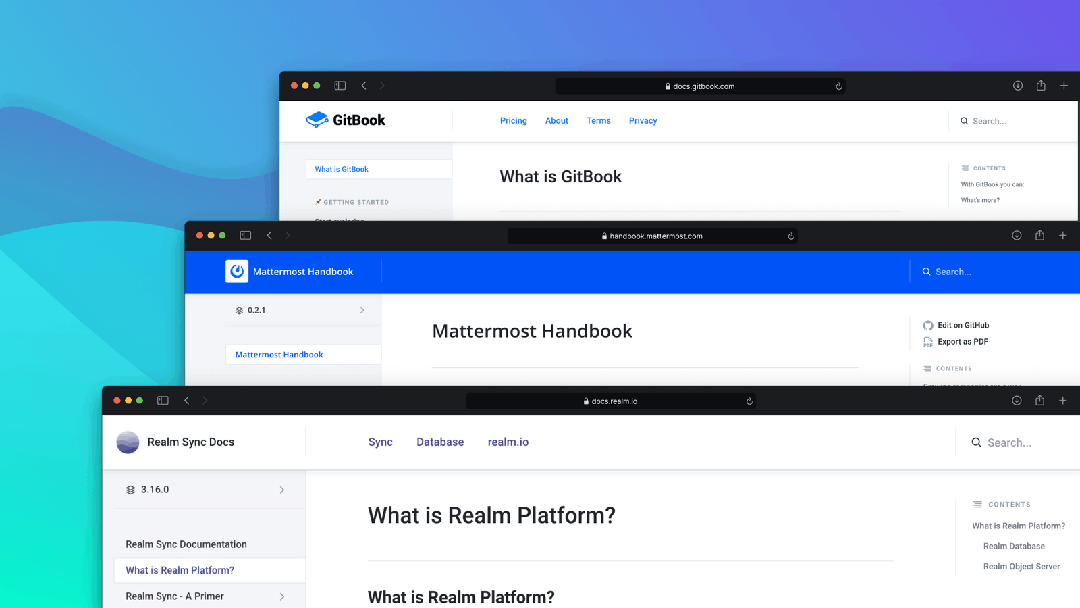
静态文档系统对于开发者来说那真的是太多了,有针对博客系统的 Hexo 和 Jekyll 以及 Ghost(顺带一说我的两个个人网站,一个用 Hexo 搭建一个用 Jekyll 搭建,各有好处吧)。偏文档的 VuePress 和 Gitbook(Web)/Gitbook(Github) 以及专门用于类似项目宣传页面构建的 docsite(Web)/docsite(GitHub)
2.4 对前端框架的吐槽
前端框架在我的感觉上比“后端”要更加活跃,也许是因为技术“欠债”比较少。同时前端技术更加激进,让开发人员切实的感受到新技术能解决他们遇到的一些问题和不方便的地方。在不考虑某些“企业级”的前端框架下,在 ES 这种相对灵活语言中做框架我认为是相当的有难度,这里的难度更主要的体现在整体规划和设计上。当然在写多了强类型语言后,看到一些脚本语言或者支持函数式编程语言的那惊为天人的代码逻辑后更加让人佩服了。
我要说的是一些非官方框架,有些开箱即用的在一些领域几乎占主导的框架,有超高的使用量。但是在很多时候是对现有技术的整合与拼装,并形成的 demo。无论是整个文件组合方式,命名,模块划分甚至是骨架代码都写的非常随意。这类脚手架项目很多时候拿来用都不可避免的要重构,以及解决由于代码不严谨产生的各类 bug。并且没有文档和说明,代码库的东西和演示的demo存在差异。
说到文档我就是更加郁闷了,前端的一些官方框架比如 ant 或 element 这些有非常详细的文档和 demo。但是后端即便是一些大厂文档也少了可怜,wiki上寥寥几页也基本是介绍,快速开始。稍微有一点个性化设置反而要去 issues上找,遇到莫名问题只能去看源码,更不用说大多情况下源码除了文件头的声明外也是干干净净。
3. 后端
后端的设计在 Java 领域很多时候已经进入了近乎“偏执”的状态,很多时候完全不考虑自身的业务和实际需求而去追求大而全的方案。和现在一些小公司莫名其妙一定要上 K8S 一样,首先要考虑业务是否需要,其次公司内部的IT资源是否能支撑的起来。
某一天有个朋友让我给他做个小系统的三发授权接口说急着要,我想这不简单吗 Spring 全家桶来一个多快。于是在我打开IDEA后思考怎么分模块,怎么设计传输协议格式,怎么做权限控制,如果怎么怎么样,那么如何应对,然后创建了好几个 markdown 文档开始写。没写多久突然意识到分析个锤子,考虑这么多干啥,于是马上动手写。没过多久又不自觉的开始写基础组件,各种工具类,我开始发觉过于条理化的Java以及成熟的“工业”规范让人几乎不敢去写一个简单的“Hello Word”去用。
于是我关掉 IDEA 打开 VSCode ,打开 KOA 官网看了下入门介绍没一会儿就写完了这个小功能,一年多过去了在一个低配置的腾讯云服务器上用PM托管下一直安静的运行。在Java领域很多时候已经是面向规范开了,即便是业界已经证明没有问题的其他JVM语言也很少直接拿来开发,更别说多语言的异构系统,如 Java、python 和 NodeJs 混合开发一个项目。很多时候我在写完 Vue 保存重载后回到 Java代码看一下代码逻辑,觉得有问题改一下就会不自觉想这么改是不是违反了什么什么原则,是不是该封装一下提出来做个公共类?真的是累,也许正是由于这种原因,Java的规范越来越复杂,越来越成熟,我们亲手写的越多反而由于必定不会考虑的面面俱到,所以“低代码”的思想又一次成为潮流?无论是自动生成代码还是逻辑脚本编程是否会取代实际去写代码?
3.1 文档转换

后端对文档的处理和很多时候也是非常头痛的,特别的Office这种。虽然很多语言对Office文档都提供解析,有如Python之类处理Excel相对简单便捷的,也有像Java领域Apache POI这种功能较强但是难用的飞起的库。特别是Java这边基本每一种文档的解析都有强大但是难用的工具,这其中还有各种各样的坑。这里就不得不推荐一个通用的非常强大的文档装换工具pandoc(Github)/pandoc(Web)。当然这也不是万能的,遇到不支持的还是要乖乖的自己解析。
3.2 文本处理
文本处理是这个项目的核心,首先是数据存储,先上 Mysql、有问题的话换 MongoDB 或者 CouchDb。
文档处理基础功能包括,通用的标签管理,分类管理(多级或单级笔记本)之类一般意义上行的数据操作,这也没什么好说的,直接用关系型数据库配合ORM框架。
这里要做的是自动关键词提取,摘要提取。以及之后体添加外部知识读取时的自动分类,正文提取等。
3.2.1 分词
在中文环境中想做文本的分析处理,分词是无法避开的第一个环节。以前分词这个概念很少进入大众视野,似乎也是在移动互联网大潮中过往积累的大量数据开始发挥作用,伴随着大数据系产生的效果切实的影响到我们身边的事物。以及之后成熟的机器学习相关框架与工具,让一些比较高级的文本处理一下子简单的起来。
这里也不在多说分词的技术原理什么的,比较知名的几个分词器有:结巴分词、ansj分词器、中科院计算所NLPIR、哈工大的LTP、清华大学THULAC、 斯坦福分词器 (Github)、Hanlp分词器、KCWS分词器等。
这里采用了ansj项目进行了初步测试
1 |
|
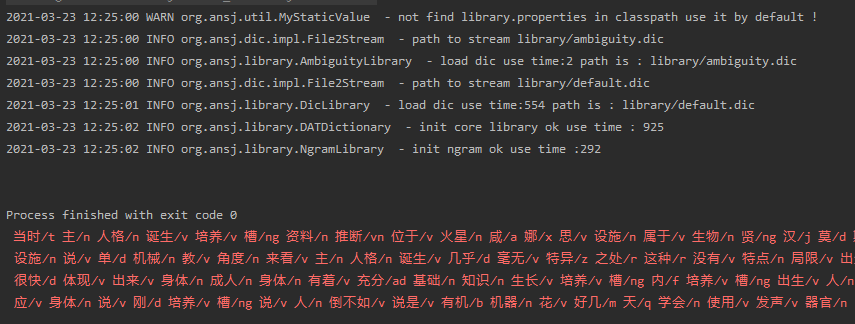
对于一般的大段文字还是可以的,也许是受限于默认的字典。一些比较偏门或者专用名字切分的有些问题,这也是可以理解的,专门的领域可能要使用专门的字典。
3.2.2 关键词
关键词提取也是比较成熟的技术,有很多成熟的理论。如果没什么要求那么直接暴力的做一下词频统计已经能满足大部分需求。这里应用环境更多是文章文本,那么先使用TF-IDF。
1 |
|
在第一次没有添加Stop word,计算结果有非常多的与文章主题无关的修饰词出现。在初步看了下源码后,对源码进行了部分修改。加入了一些对修饰性词语的限制得到以下结果。
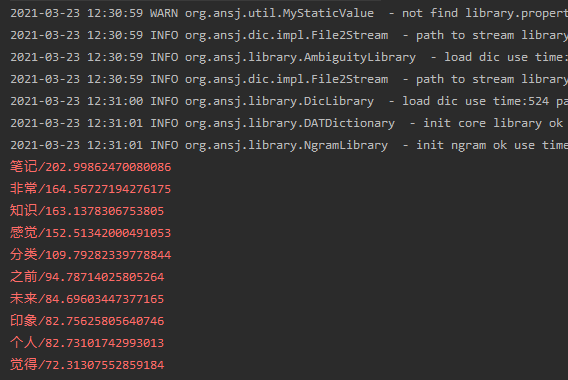
结果虽然是能看了,不过依然我写作时想要表达的观点有出入。这可能是一些写作习惯,或是文章本身就没有准确的表达出本意,当然了还有可能是通用的字典问题。这在后续要进行排查。
3.2.3 关系挖掘
正文提取与文章摘要暂不进行说明,很多NLP库都自带并且效果还都不错。
说到挖掘好像是什么很高深的东西,但是仔细想一下这种关系的法线本质不就是一个分类方法,无论是相对简单暴力的KNN、余弦或者是协调过滤。其本质就是分组与分类,最终拿到组里的东西做文章。
而这次让我吃惊的Word2Vec。很早之前也听说过似乎是文本处理领域非常厉害的东西,但是一直不知道是做什么的,这次测试一下结果让我无法理解。在看了Word2Vec原理介绍后才发觉是自己用错了。
1 |
|
拿之前的文章做分词后生成语料库,再使用语料库生成模型。这个模型里记载着文章分词后的词向量,这个词向量模型本质就是用来计算与输入词语的相似度。
这个模型可以感性的理解为,将某个词语的上下文中与其有关的词语全部记录下来。模型中实际的向量是一个词各种“颠来倒去”,所以这个模型会比原始文章大很多。
现在利用模型计算“距离”
1 |
|
计算结果如下,这篇文章里与“笔记”这个词“距离”相近的词有如下几个

那么这有设么用呢?确实这个例子意义并不大,当时我也是这么想的,但是我看到这个具体应用时才恍然大悟。这里将文章抽象化,这个文章本质就是一堆词语的堆砌,对于代码或者机器来说根本不懂词语的意义,以及这些词语为什么要用这种顺序连接在一起。换个角度说代码为什么要懂这些?代码只要知道若干次会以不知道什么的规则连接在一起,那么它们一定存在某种明显的或潜在的规则(实际上没必要去做语法或逻辑上理解)。那么只需要将这些词的上下文关系记录下来,标记这种关系那么就能使用这个模型反应一定的词语见关系。那么将这个词语换成人名,换成商品名,不就反映出他们的客观联系吗?
所以用Word2Vec的关键是要找到一篇“文章”,之所以叫文章是因为必须保证文章词与词之间存在某种联系,而不是一堆随机字符。但是这种联系也不一定是语法或文字逻辑上的,它确实可能是全篇的随机字符或乱码。最终目的按照词语排列顺序建立起词向量来反映他们之间的关系。比如我的购物车中的购物列表。
先写到这里吧。