图像标签管理-Deepdanbooru
前几天还在为 pytorch 如何部署以及如何融入到图像处理流程中苦恼,没想到图片分类这边在短短几小时内给调试过了,并迅速融入到整个图片处理流程当中。
其实这也很容易理解,以图搜图的图像识别需要多次经过专用算法:
- 特征值提取:通过
pytorch调用模型提取特征值并存储起来。 - 计算特征值:由于特征值的量级比较大,并且又不是简单的数值或字符串匹配,而是调用专门的算法。
虽然可以将图库图片在后台预先处理(这里可以与业务流程分类),但是用户上传还是需要在业务流程中在进行特征值提取以及特征值相似度计算,在没有足够算力的情况下,这个过程非常影响使用体验。相反标签搜索仅仅是数据搜索匹配问题,一下子就将一个看似复杂的算法问题转换成一般意义上的业务数据处理问题。
这里就简单介绍一下基于 deepdanbooru 的图片分类以及衍生出来的标使用标签进行与管理的问题
TL;DR点击列表跳转
1. 环境搭建
当前最新模型基于20221112(实际就是时间)数据集,使用 RTX 3070 训练而成。将基于 TensorFlow 的python 代码下下来,就可以直接跑了。
当然在 windwos 平台需要装
CUDA,cuDNN,以及zlib 所需的zlibwapi.dll
入口在 _main_.py 文件中,而核心代码都在 commands 目录。由于硬件资源与样本资源限制,这里就不做模型训练,直接使用上文的模型。
1 | deepdanbooru evaluate [image_file_path or folder]... --project-path [your_project_folder] --allow-folder |
官方代码如上所示,
- evaluate:参数最终会调用
commands/evaluate_project.py - image_file_path or folder:图片路径,或图片文件夹(批量识别)
- your_project_folder:就是模型文件下下来解压收的目录,后续需要读取里面的模型文件,项目配置文件,以及标签文件。
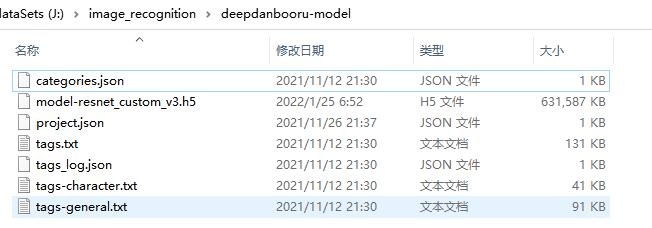
模型文件加压后如上图所示
- categories.json:似乎记录的的标签文件
tags.txt中三种标签分类的偏移量 - model-resnet_custom_v3.h5:这就是模型,也就是
深度残差网络(Deep residual network, ResNet)。 - project.json:这就是配置文件了
- tags.txt:标签总汇,是
tags-character.txt+tags-general.txt+ 三个分级项的和 - tags_log.json:标签日志,不知道是学习的日志还是什么,暂时没有看训练模型的代码,就先不管了
- tags-character.txt:角色标签,人物标签和作品标签
- tags-general.txt:通用标签,这里面包含的内容相当的多,如颜文字,动作,身体部位,表情等方方面面。(把标签导入数据库后发现总共有九千多个,相当惊人)
当时咨询一个机器学习大佬图片分类怎么做,推荐我去了解
Mask R-CNN,也正是查询了CNN相关资料的时候无意间发现了deepdanbooru这个模型。
1.1 测试
废话不多说先跑起来
1 | import sys |
先随便写个 python 文件直接调用
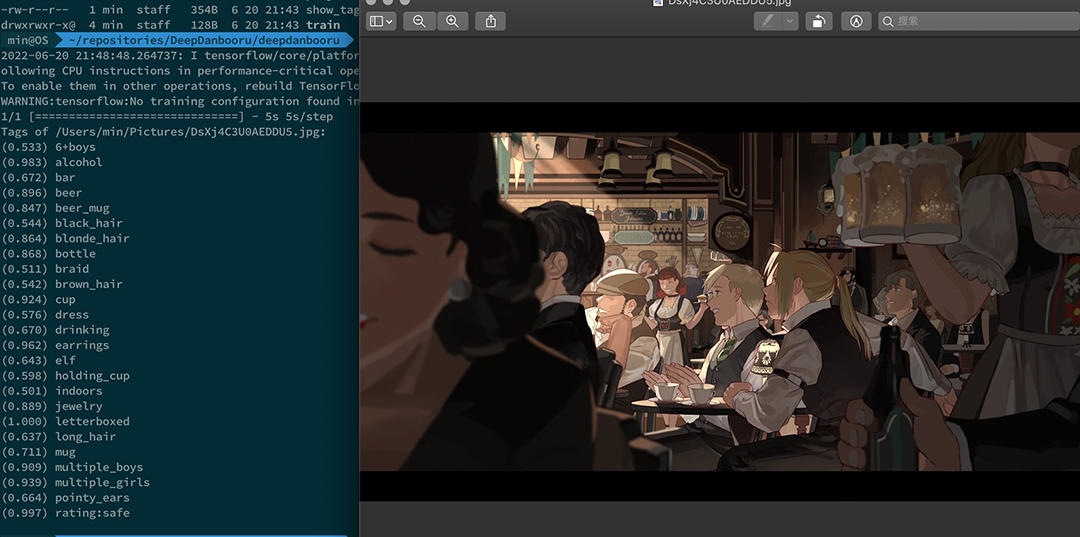
第一次测试一个大小和像素都比较高的《钢之炼金术师》的图。虽然没有识别出作品和人物,不过已经感觉相当不错了。可能是剧场版这种画风与一般TV版差别过大,也可能是样本本身就不足。
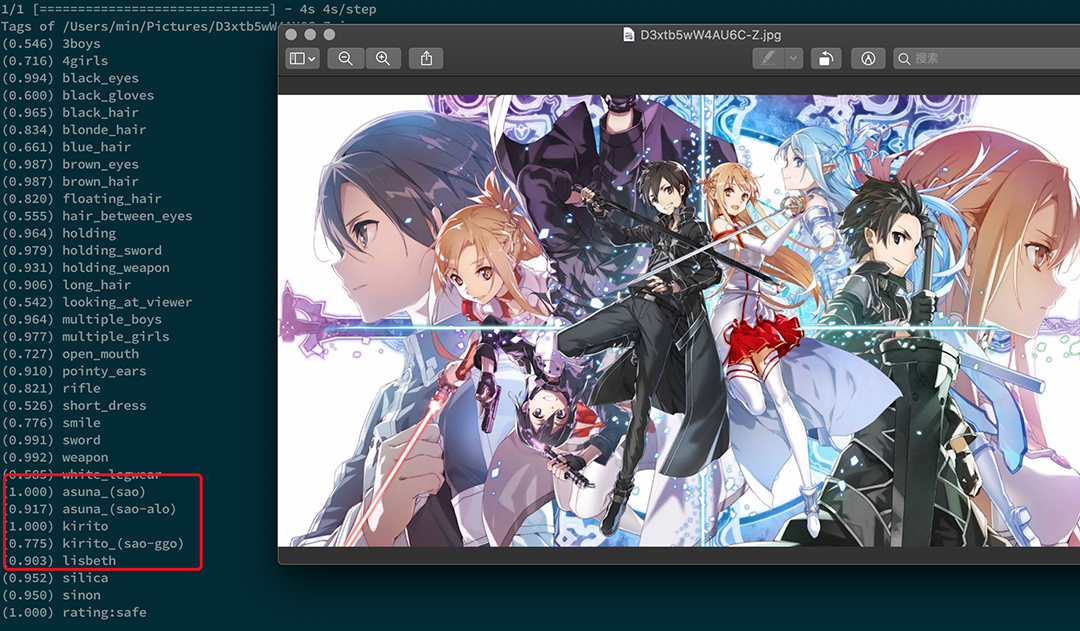
然后就是重头戏,找了个 SAO 的图。
让我惊讶的不是能识别出人物,而是识别出了同一个人物在不同作品中的形象。看到这里我觉得就用它了。
随后咨询了某机器学习大佬模型训练的原理后得出结论,算法模型这种都是 何恺明 这巨老去研究的。我们日常使用实际上就是调参数,所以理论上只要样本数量足够多和分类做的足够好,那么无论多么刁钻的分类都是没有问题的。
由于在 Mac 上跑感觉代码跑起来比较慢,似乎是显卡不行的样子。于是后续真正干活转移到 Windwos 上。
第一次跑
pytorch时候在装完CUDA后在一个选插件的网站上拼接出一条执行语句,怎么做都执行不了,而且又跳到 VS 安装界面。由于我实在是不想装 VS 就放弃了。这次装TensorFlow只需要装cuDNN,也就是几个 DLL 文件复制到相应的目录就可以了。
2. 改造与使用
2.1 代码说明
1 | def evaluate_project(project_path, target_path, threshold): |
实际上核心代码如何使用模型就如上述所示
其中读取项目配置信息为 dd.project.load_project(project_path) 位于 /project/project.py 方法 def load_project(project_path) 中。
加载模型语句 model = tf.keras.models.load_model(model_path, compile=False) 在 windwos 平台报错说要编译模型,这里传入 compile=False 参数忽略错误。
其实还会报错一个方法引用错误,属于 python 调用的问题,顺手改了
为了使用显卡提高效率现在换到 windwos 平台后找了张甘雨的图试了一下

说实话很满意,对于目前的应用足够了
2.2 代码改造
首先我的旧电脑使用机械硬盘,显卡 GTX 1650 加载模型的时候总报错显存不足,但是似乎也没有影响后续使用。在 github 上看到有人问怎么限制显存的使用,看到了以下一段代码
1 | def limitgpu(maxmem): |
但是经过实际测试完全没有用,之后先看看TensorFlow2 的API改动,再就是升级一下设备。
首先是准备工作,在NAS 中装上 minio
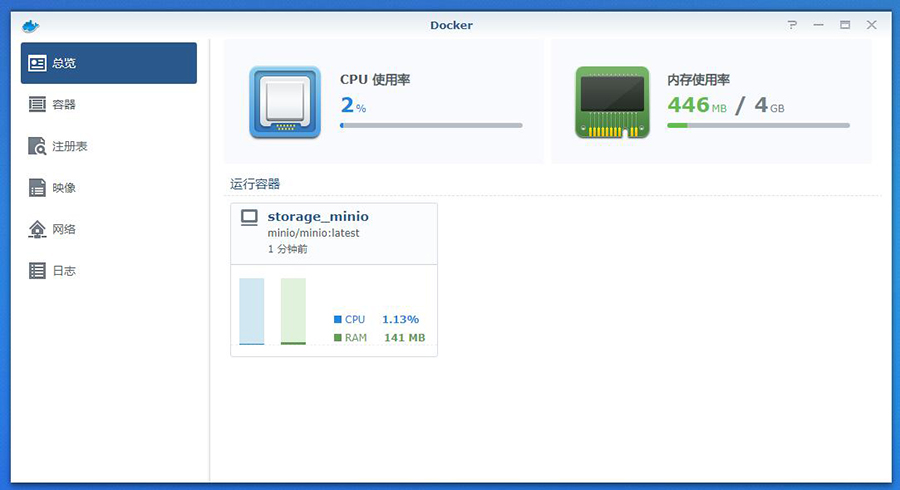
在 docker 中跑一个 minio 并把配置文件与存储目录映射到其中一个磁盘上。
对于 NAS 设备我实在不想通过 SSH 连上去启动服务了,使用UI管理多舒服。
我的资源管理和分析服务使用 JAVA 编写,本来也想打包成镜像在界面是操作,同时又能直观的看日志多舒服。但是考虑到其中代码用到 JCE 相关代码,用到了一些 RSA , DES, AES 以及需要SSL库的支持。每次在部署到一个新的 linux 上总会由于 JDK 中 JCE 版本差异报错各种问题。如果我打包一个 配置好的JDK 到镜像中有感觉太大了。同时考虑到代码可能在数据跑完后频繁改动,就先直接 ssh 进去启动 jar 算了。
随后我在 JAVA 中开启一个同步任务跑了将近两天从服务器上拉下来两万张图,现在写这篇文章时已经到四万。这些图中数据有一半是缩略图,在跑代码时使用一万张图做基础数据。
同时考虑到机械硬盘可能在大量碎文件转移过程中影响效率,于是在 windows 上直接挂载磁盘的方式减少本地磁盘读写,将多次磁盘 IO 转换成网络 IO。
整个过程的思路是这样的
- python 调用 java 远程接口分段查询媒体数据库中存储的文件名
- python 在拿到文件名后拼接到远程磁盘路径后,直接读取远程文件。
- python 调用
TensorFlow算法模型输出标签后,再调用 Java 远程接口将文件ID 和对应的标签转给Java 服务 - Java 服务将文件和标签关系存入数据中。
代码如下,直接改已有的源码
1 | headers = { |
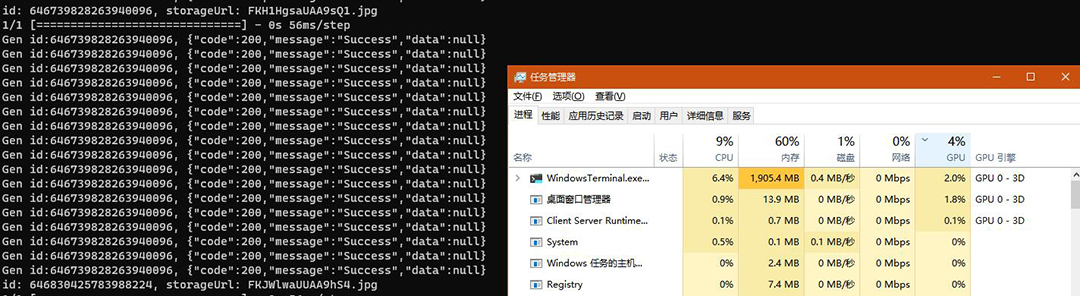
启动时内存占用在 2G 上下,之后稳定跑起来内存维持在 400M ~~ 500M 左右。真正跑起来后依然无法确定到底有没有使用到 GPU ,因为这个使用率太低了和快速拉一下窗口占用的GPU差不多。后来我想调用显卡本质用的是CUDA,那就看看 CUDA 的使用情况。
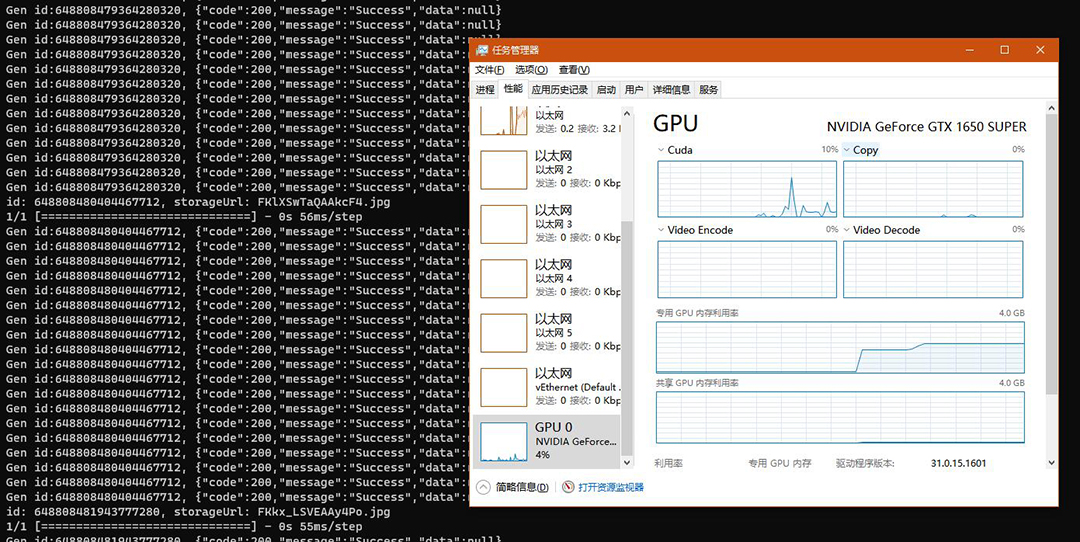
可以看到 GPU 的 CUDA 在启动时也相当的高,稳定后保持在 10% 上下。物理显存实际上只有 2G 直接爆满。
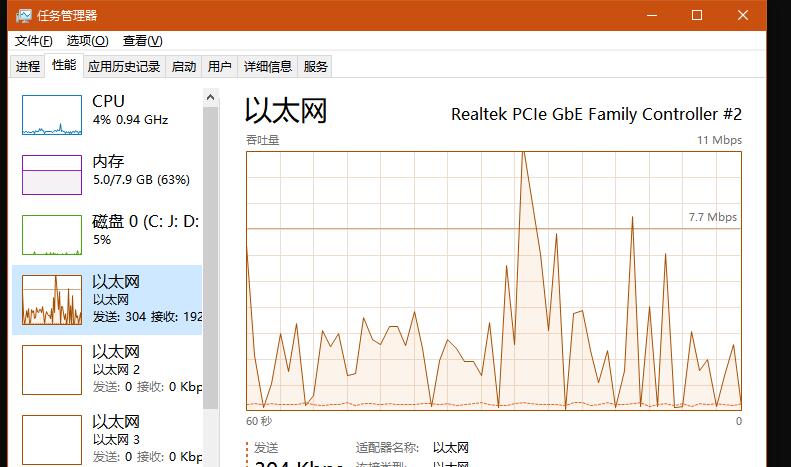
由于这些图片相当于大量碎文件,可以看到以太网流量波动比较厉害,磁盘可以认为是波澜不惊。
2.3 总结
整个一万多一点图片打tag,从 15:50 到 20:09 也就认为是跑了四个小时吧。在这个过程中资源消耗
| 资源名 | 使用 | 说明 |
|---|---|---|
| 内存 | 400M ~ 500M | 基本维持在420M,波动可能是读到大文件了 |
| CPU | 2.5 % | 看来不怎么消耗 CPU |
| GPU | 3D 没有,CUDA 10% 左右 | CUDA 的波动应该是遇到比较复杂的文件 |
| 显存 | 爆满 | 估计要至少 8G |
| 数据集 | 1.2 万 | |
| 生成标签关系 | 10万 + |
仅从资源消耗来说还没有用浏览器看一个视频消耗大。
之后升级一下硬件,用我自己的样本跑出来一个模型再看看
3. 标签管理
这才是重中之重,前面忙活这么多不就是为了干这个的吗。
标签管理是我思考相当旧的功能,可能是我考虑的东西太多了。
就标签本身来说包括:语言,同义词与近义词标签,标签分类,标签分组,以及多维度的权重问题。
对于同一个标签来说不同语言是属于同一个来管理还是在按照权重划分为不同标签?
很多分类意义非常近,那么算是一个标签还是多个标签?
标签太多在使用时无从下手,是不是加一个分类?
看起来毫无关系的标签可能属于某个抽象概念?为了便于联想搜索,是不是需要将这些标签划分到一个抽象概念下?
如 舰队收藏 ,某一天我想搜索一下相关图片,我可以搜 kancolle,舰娘 ,舰队收藏, 舰C,甚至是 砍口垒 (额,这个还是算了)。
如果不做这个分类或关系维护,那岂不是要有一个表格要去查一下?默认便签编码是 kancolle ,要想搜其他的抱没有,自己去查表。特别是一些比较偏门的标签,甚至无法找到。比如先搜黑丝,那么到底是搜裤袜还是 panty 还是那什么 …
特别是这个领域有很多专有名词,不够 二 根本就不知道 …
同时这里面的标签很多是日语罗马字母直接拼起来,比较偏的角色名要反复来回读几遍甚至都猜不到…
太难了,先不管那么多了。上成果
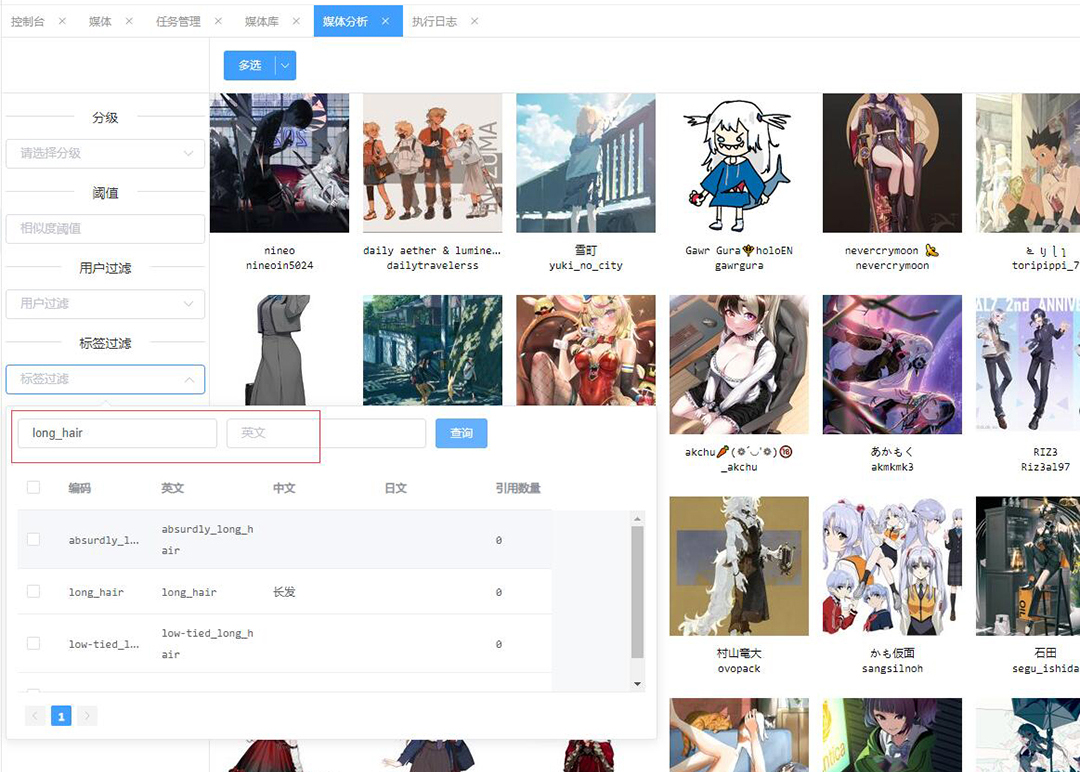
首先使用编码搜索中直接模糊出来所有包括 long_hair 的标签并全选。
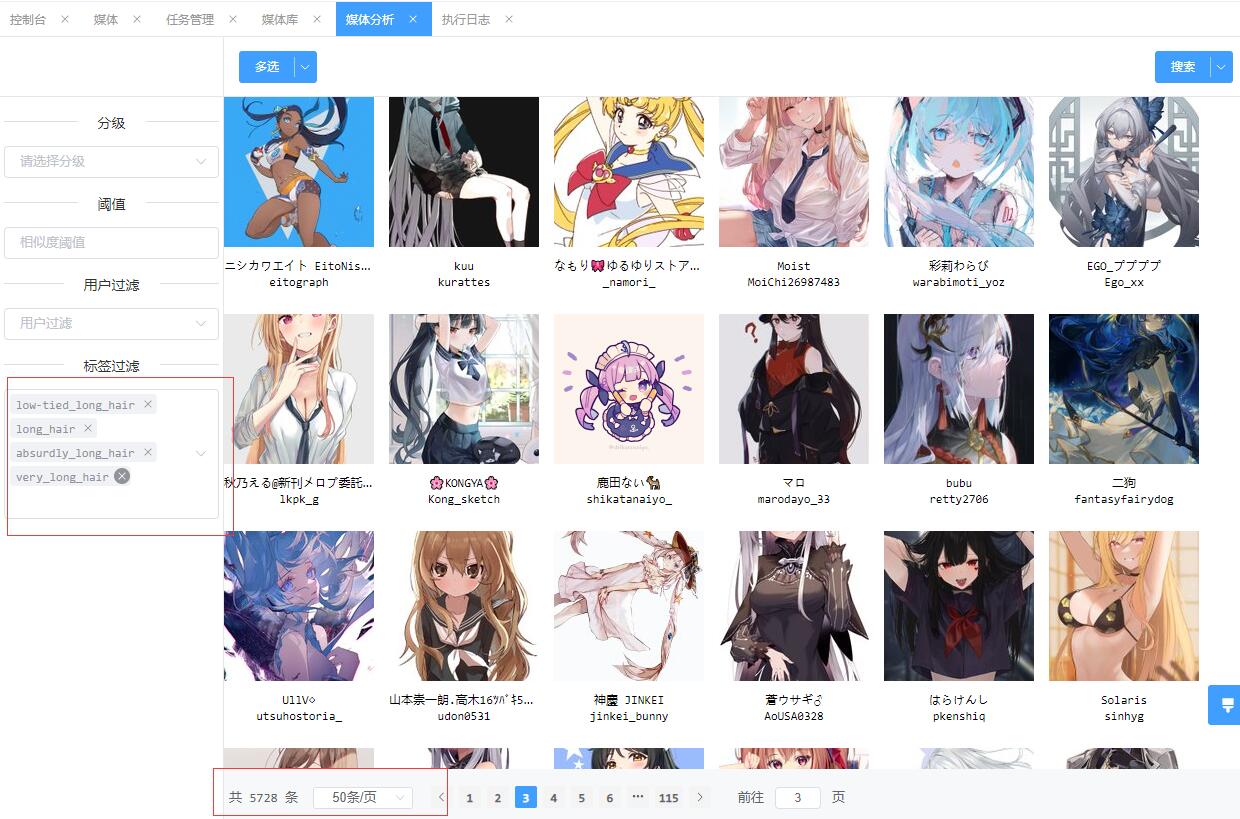
可以看到效果是达到了,但是和我想的还有较大差距。因为我要找的特征并不知道标签库里叫什么,无论是编码还是英文名。
好不夸张的说分类对人类来说都是一个困难的问题。对于普通人定义的分类是非常的粗糙,粗劣,不严谨,随意性强。大多时候是根据生活经验甚至情感,但是分类一旦到达一些观感上相近或模棱两可领域,最终结果就会与直觉相左。因为用户大部分都是感性的普通人,这种矛盾几乎无法有效的结解决。
4. 问题
最后说一下遇到的问题。首先机器学习与深度学习的通病,那就是规模取胜,可以简单粗暴的认为是一个统计学问题。即在一个足够大的数据集样本上,保证输出一个总体来说比较满意的结果。如果从数据集中任意选一个小样本集合那么结果就完全无法预测,当然了从算法和模型角度来看这种情况属于噪声吧,但是对于用户来说就感觉莫名其妙了。
针对我目前的实际情况来说是基本可用的,但是针对特殊风格无法识别。观感上是同一个人但是分类却不是,甚至明显不是一个人,却识别成一个人。如将一个兔女郎手办识别成原神里的芭芭拉,将一个红发角色也识别成原神里面的迪卢克。
很有个人风格的图片人物就无法识别,一些比较小众的作品也只能识别出身体部位
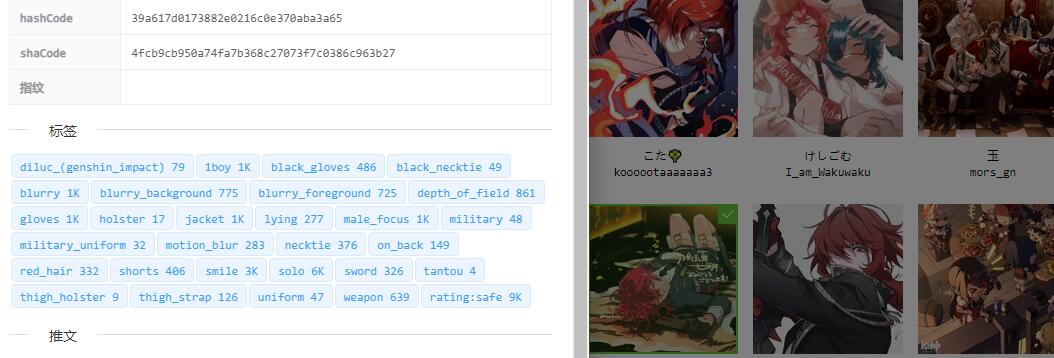
比如这个刀剑乱舞的角色识别成了迪卢克,其实这个还比较容易接受毕竟确实有点像。但是这暴露一个问题,那就是必须有标签的编辑功能,但是编辑标签这个工作量想想就觉得可怕。我最初的想法就是图片太多无法人工分类,又不像那些 UGC 社区那样用户自己编辑。
这有引出另外一个悖论:
- 我对这个模型不满意,分类没有达到我的预期效果,我需要自己训练模型
- 训练模型需要足够多的已分类好的数据集,但是这个数据集又是哪里来的呢?
难道要小部分分类数据训练,再分类,再训练这样一步一步扩大规模的方式吗,想想都累 …
5. 最后
图片的标签管理功能在应用上迈出了第一步,但是离用起来舒服以及定时分类新图还有比较长的路要走。以及与这个功能相辅相成的以图搜图,如何融入操作和使用流程,还需要继续摸索。