
愿此行,终抵群星
正值琥珀历 2157 纪结束,2158 纪到来之际,我们期盼银河各处携手并肩,守护美好家园。
在过去的 2157 琥珀纪,神秘现象「星核」造成的污染仍在继续。「星核」阻塞了文明之间的道路,令一度团结在「琥珀王」命途下的诸界分崩离析。在博时学会的鼎力支持下,我们已初步掌握了绕过星核污染的技术,并在一百一十三个星系进行了实验,取得了可喜的成果。
在寰宇人们深受星核困扰的同时,一伙新兴起的邪恶组织「星核猎手」却在宇宙中四处作乱。根据最新消息,他们上一次出现的地点是仙舟「罗浮」。「星核猎手」成员被划定为极度危险份子,任何一名成员均有独自覆灭一颗星球的能力,如遭遇疑似星核猎手的成员,请立刻联系公司,切勿打草惊蛇。
已陨的星神,「开拓」阿基维利曾搭乘的星穹列车如今重新启航。在浩瀚无边的银河中,我们并不孤单。在此,我们代表星际和平公司向星穹列车的开拓者们送上最真挚的祝福。
在琥珀 2158 纪的开端,星际和平公司骄傲地宣布:天才俱乐部著名学者黑塔女士,已正式承诺与公司达成长期友好合作同盟关系。这将是第 22 号会员利尔他、第 56 号会员以利亚萨斯之后,第三位智识的天才与公司携手,共同存护琥珀 ...

《铃芽之旅》个人评论
回想起上次看《天气之子》似乎没有多久的样子,在看了下观影记录后发现其实已经过去挺久了。
说起来自从《你的名字》后我就在想,会不会这之后的作品越来越“规范化”与“标准化”?因为《你的名字》总体的观感是太“标准化”了,如果类比的话就是《绿皮书》的那种感觉。似乎都是在按部就班,无论是情节走向,还是精确的时间控制。《天气之子》除了因为人设是“田中将贺”让我一度感觉比较出戏外,总体是比较满意的。
《铃芽之旅》我的第一印象依旧是人设有些出戏,在男女主角相继出场后才慢慢的适应过来。然后就是一种莫名的关于《哈尔的移动城堡》的既视感,无论是人物还是场景,并且这种念头还总是突然跳出来。当然了,在抛开以上这些(都是个人主观感受)以及“世界系”这种设定后,这部作品是非常不错的。
也许是日常看番剧常会遇到奇怪的设定,以及莫名其妙的剧情展开的原因吧。新海誠的剧场版动画先不说惊人的作画,剧情发展还是没什么大的问题。从这点来说是相当放心了。
《铃芽之旅》的主线是关闭通往常世(异世界,死者的世界)的门,否则灾祸就会经过门降临于现世(主要以地震的形式)。在这个主线的大背景下,我认为都是女主角 “岩户铃芽” 推着 ...
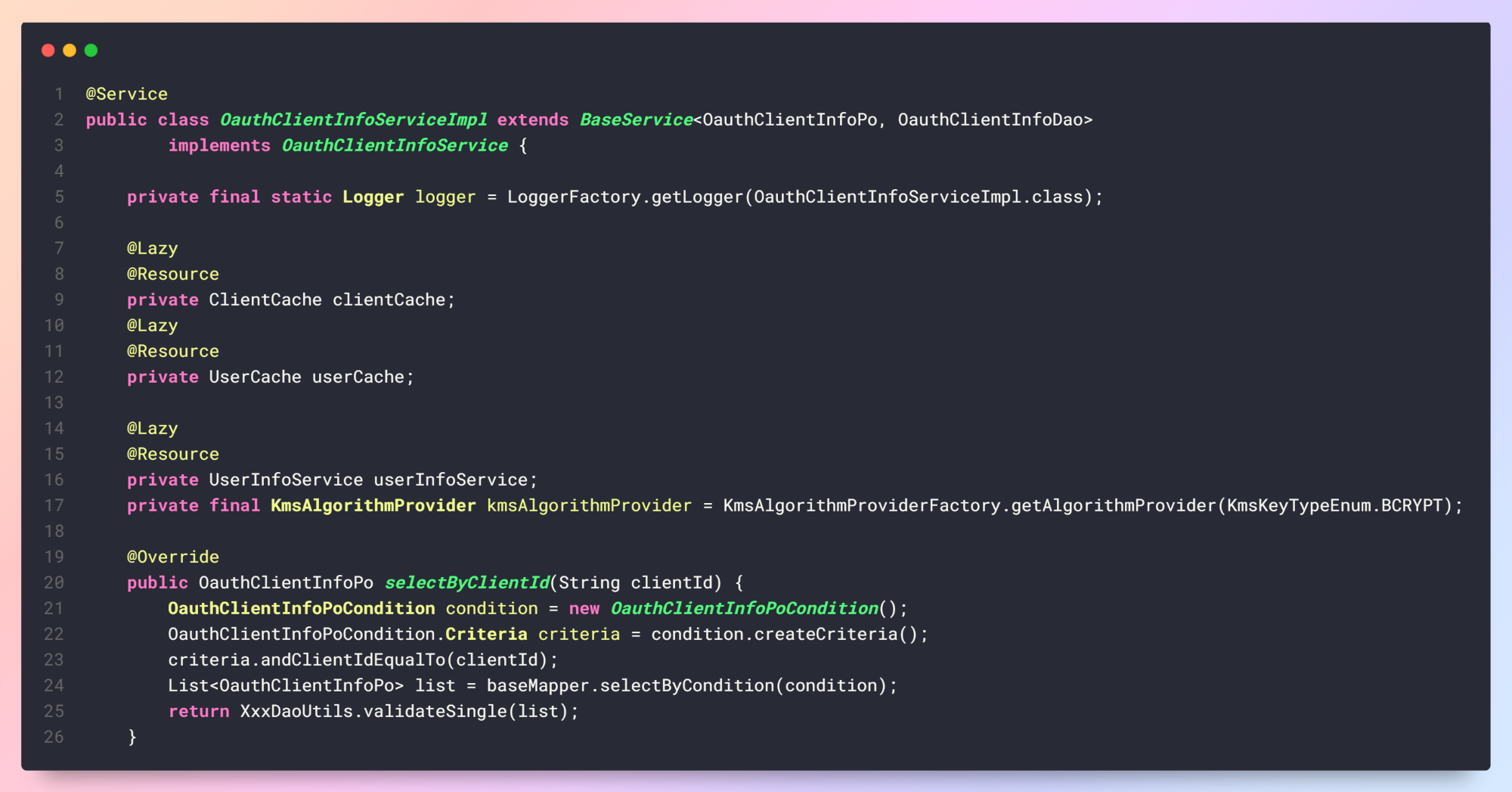
使用MBG的代码生产思路
这里的代码生产思路限制在持久层,也就是主要用来产生 DAO 和 PO 。主要作用是根据数据库设计反转出相关代码,并使用规范设计出一系列数据操作接口。以便在实际使用中统一数据操作接口,减少数据操作的模板代码编写。
持久层的生产使用 MBG 也就是 MyBatis Generator ,数据操作行为使用 XML 描述。生成器 Runtime 使用 MyBatis3 。在这次的系统升级中发现 MBG 提供了 Kotlin 的支持(MyBatis3Kotlin),同时默认 Runtime 已从 MyBatis3 更改为 MyBatis3DynamicSql 。之前看了下动态 SQL 的介绍觉得有些细节不是很直观,现在看来动态 SQL 似乎要成为主流。后续了解一下。
1. 设计规范要想做统一操作必须要首先制定规范,这个生成器的目的就是规范 DAO 和 PO,所以需要设计一个 DAO 和 PO 的顶层接口。
123456789// 所有 PO 的父类,实现一个框架级别的 IEntity 接口public abstract class BasePo implements IEntity ...

Spring Security 升级到 6.0
整个系统在认证与授权使用的是 spring-security-oauth2 ,早先想做升级的时候看到官方出了个 Authorization Server 。去 Github 和一些社区看看发现这个项目还比较早,且不是很活跃,于是想等到稳定一些。
现在打算升级到 6.0 版本就需要整个 spring 关联框架全部升级。所以整个过程包含以下问题:JDK 17, Gradle,SpringBoot, SpringCloud,数据库相关,重要的独立三方库,Oauth2,业务代码,框架代码。
TL;DR点击列表跳转
构建环境
JDK 17
Gradle
Spring相关
SpringCloud
Spring
Spring Security
最后
1. 构建环境1.1 JDK 17这方面从静态代码的角度来说其实在升级过程中影响并不大。
当把 JDK 17 引入项目后点开项目的 External Libraries 的瞬间我就觉得,无论升级有多麻烦都值得了。和 JDK 8 相比这舒服的模块分类,简直是自己知识体系归类的官方规范。
值得注意的是 @Deprecated 这个注解
...
Spring Security 开篇
当前内容基于 spring-security 5.3 ,在升级到 6.0 后内容会随之变更。
这篇文字就站在整个 spring-security 的层面整体,快速地聊一下,目的是对这个框架有个比较感性的了解,大致知道这个框架有什么用,以及如何使用。
TL;DR点击列表跳转
Spring Security
运行流程
构建流程
知识点
最后
1. Spring Security提到安全我想如果简单的概括,我们要做的就是 “访问控制”,而访问控制的目标就是 “受保护的资源”。那么安全管理的功能点就可以简单的概括为 “认证管理”,“授权管理” 和 “资源管理”。
资源管理这个概念从编码角度来说是比较难以概括的,因为资源这个概念的划分本身就有很强的主观性以及具体的业务逻辑特色。在很多情况下,特别是对后端系统来说,资源被抽象成为访问路径(rest 接口)。这就一度让编码人员忽略“资源”这个概念的准确意义。(所以这里先不讨论资源管理)。
“认证管理”,“授权管理” 不仅是中文还是英文,如果没有思考过这两个概念我想都会感到困惑。
认证 :authentication 字面意思,就是允许 ...
接口同步wiki.js
首先简单说一下之前使用印象笔记给我带来的思考。
印象笔记不支持多层级,那么就需要 001-层级1-002-层级2 这种将从属的树形结果,转换为同级别的平坦结构。这带来的问题是什么?全都挤在一起,看着非常烦躁。
所以我觉得印象笔记的定位实际上是收集,而不是知识消化整理和输出。
几乎所有知识的逻辑组织结构,在当知识或素材规模达到一定量之后都将失去其最初的意义。这一点在目录结构(或者说树形结构)膨胀起来后尤为明显。目录结构本质是对知识素材的人为分类,在初期由于其非常符合我们日常的分类习惯,这几乎是下意识的水到渠成。不过这首先需要面对内容的是排他的唯一分类,当你对内思考的越多就越是难以取舍。这时候除非在专有的领域或者经过专业的训练,否则知识是无法简单的的划归在某一个层级目录下。无论是知识录入还是知识获取,每次可能都有新的分类想法,结果是这些输入输出非常困难。那么这时候目录结构就只剩下一个作用了,那就是目录树的某一子树是一个相对完整的,成体系的知识结构,我们做复习与整理的时候想办法在这棵大树下找到子树,然后按照最初的目的使用知识。
其它的如标签模式,多维度管理模式,进而发展成类似知识 ...

使用 Wiki.js 初步构建知识库
我个人一直困扰于个人知识的管理,包括一些静态资源,各种文本片段,以及总结输出的结构化内容。而这一切的目的就是在我需要的时候能快速找到它们。
经过深入的思考,以及做了一些尝试后发现,这个目标远比我想象中的复杂好多。于是我决定将要求放低一些,以 wiki 的方式对知识进行管理。在对比了一圈后发现,非常轻量化的 wiki.js 满足我的需求,于是从 Github 把代码拉下来尝试了一下。
TL;DR点击列表跳转
1. 知识库构想
1.1 输入输出分离
1.2 Wiki
2. Wiki.js
2.1 快速开始
2.2 虚拟文件夹
2.2.1 目录切换
2.2.2 排序
2.3 功能
1. 知识库构想对于自己的知识库,初步设计了一个满足通用场景的是数据库,又参考了一些开源 wiki 的数据库设计。之后发现我i的想法和很多系统实际上有较大区别。
在我设计的系统中实体信息分为如下几个维度
材料:(暂定名),是一些不归类于业务的数据,包括直接引用的文件,图片等。最直观的体现就是一篇文章中临时上传的图片,这类数据全部在业务上无法管理。
资源:最小可管理业务数据。从一个文档,到一 ...

项目文本处理选型
这里需要构建一套文本处理系统,当然了构建系统从来就不是一蹴而就的,必须要面对客观环境与实际的需求,系统将来是什么样这谁也不敢保证。但是系统本身就是对客观与现实世界的抽象与归纳,对于系统的构建和设计从一开始又不能拘泥于当前环境。总是说了那么多就一句话,功能可以没有,但是设计一定要到位。
这里简单介绍一下我的选型路线,包括前端和后端,移动端目前又处在一个选择的路口。因为Flutter2的发布,以及明确的跨平台方向。桌面是否有能力挑战 Electron 这是我非常关心的,不可否认的是Electron是现在开发桌面应用的首选了,但是我对其运行方式一直不是很满意,因为大量的基于其开发的PC软件给我非常不好的使用体验,包括印象笔记,和大量的PC端音乐播放软件,这里特别要说网易云,最近的它的启动似乎越来越慢了。移动端在熟悉Flutter2前,先用响应式前端凑凑数。
那么基础的技术选型来说,前端 Vue/element-ui ,后端 Java 为主(可能会引入一些 NodeJS 或 Python ),数据库 mysql 做系统级支撑,如果有一些性能或业务要求那么就必须要文档数据库。文本 ...
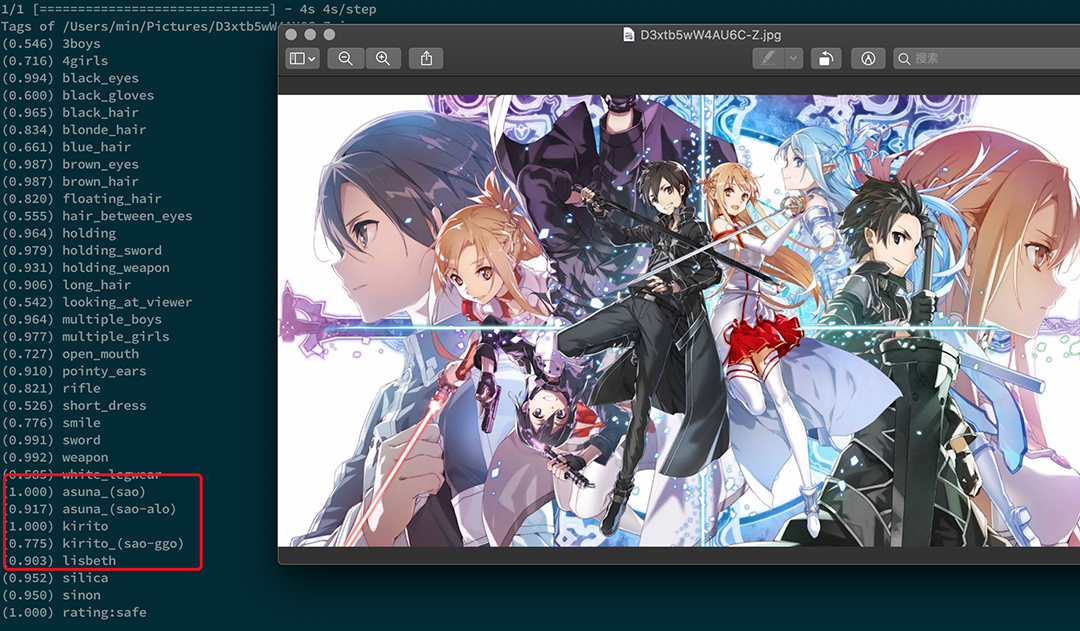
图像标签管理-Deepdanbooru
前几天还在为 pytorch 如何部署以及如何融入到图像处理流程中苦恼,没想到图片分类这边在短短几小时内给调试过了,并迅速融入到整个图片处理流程当中。
其实这也很容易理解,以图搜图的图像识别需要多次经过专用算法:
特征值提取:通过 pytorch 调用模型提取特征值并存储起来。
计算特征值:由于特征值的量级比较大,并且又不是简单的数值或字符串匹配,而是调用专门的算法。
虽然可以将图库图片在后台预先处理(这里可以与业务流程分类),但是用户上传还是需要在业务流程中在进行特征值提取以及特征值相似度计算,在没有足够算力的情况下,这个过程非常影响使用体验。相反标签搜索仅仅是数据搜索匹配问题,一下子就将一个看似复杂的算法问题转换成一般意义上的业务数据处理问题。
这里就简单介绍一下基于 deepdanbooru 的图片分类以及衍生出来的标使用标签进行与管理的问题
TL;DR点击列表跳转
1. 环境搭建
1.1 测试
2. 改造与使用
2.1 代码说明
2.2 代码改造
2.3 总结
3. 标签管理
4. 问题
5. 最后
1. 环境搭建
当前最新模型基于20221112(实际就 ...

以图搜图-Milvus
事实上这篇文章属于一个大的分类,属于个人的一个愿景。
我一直在寻找属于自己的知识管理方式,其实说起来也非常简单,满足两个基本需求:
快速找到需要的内容,包括自己总结过的结构化与非结构化数据。
组成知识网络,根据某一个关键点找到关联的知识。
经过较长时间的实践,试过了很多软件,都感觉要将自己的一套归类总结逻辑迁移去出去并被迫改变,同时又没有很好的编程接口。最终对于知识总结和录入方式选择为 Obsidian ,输出结构化 markdown 文本后通过编程完成解析和选择输出模板,同时完成知识提取和展示。
在非结构化数据管理上图像管理也是一个大难题,图像与文本不同,逻辑上的管理还停留在 TAG 或 mate dta (元数据)的层面,这最大的问题是做图片标签和分类以及元数据管理。这完全是重复性体力劳动,再加上图片存量相当大,对于个人来说几乎是不可能完成的。逻辑分类其实是倾向于准确的逻辑分析归纳式管理,目前似乎只有机器学习通过已有模型来实现。关于这点还在探索中。
图像管理上还有一条路就是以图搜图,以图搜图更像是基于观感上的,图像结构上的图片比较。对于图像风格比对也仅仅是看过文章说明,没有 ...